
멀티 쓰레딩 환경에서 캐시 미스에 대해
멀티 쓰레딩 환경에서 캐시 미스에 대해
CPU 캐시의 구조
이번 포스팅에 앞서, numpy가 더 빠른 이유 - 캐시메모리 입장에서를 먼저 보고 오길 권장한다. CPU 캐시 메모리에 대한 대략적인 이해 후 이번 포스팅을 보는 것이 훨씬 이해에 도움이 될 것이다.
컴퓨터 저장장치는 여러 계층으로 구성되어있다. 느리지만 용량이 큰 저장장치, 적당한 속도와 적당한 용량의 저장장치, 빠르지만 용량이 아주 작은 저장장치로 구성되어있다.
느리지만 용량이 큰 저장장치는 HDD 혹은 SSD, 적당한 속도와 적당한 용량의 저장장치는 메인메모리(RAM), 빠른 속도와 작은 용량의 저장장치는 CPU 캐시메모리이다.
이 CPU 캐시메모리는 또 3가지 계층으로 구성되어 있다. L3, L2, L1. L3 캐시가 가장 느리고 L1 캐시가 가장 빠르다.
L1 캐시, L2 캐시, L3 캐시
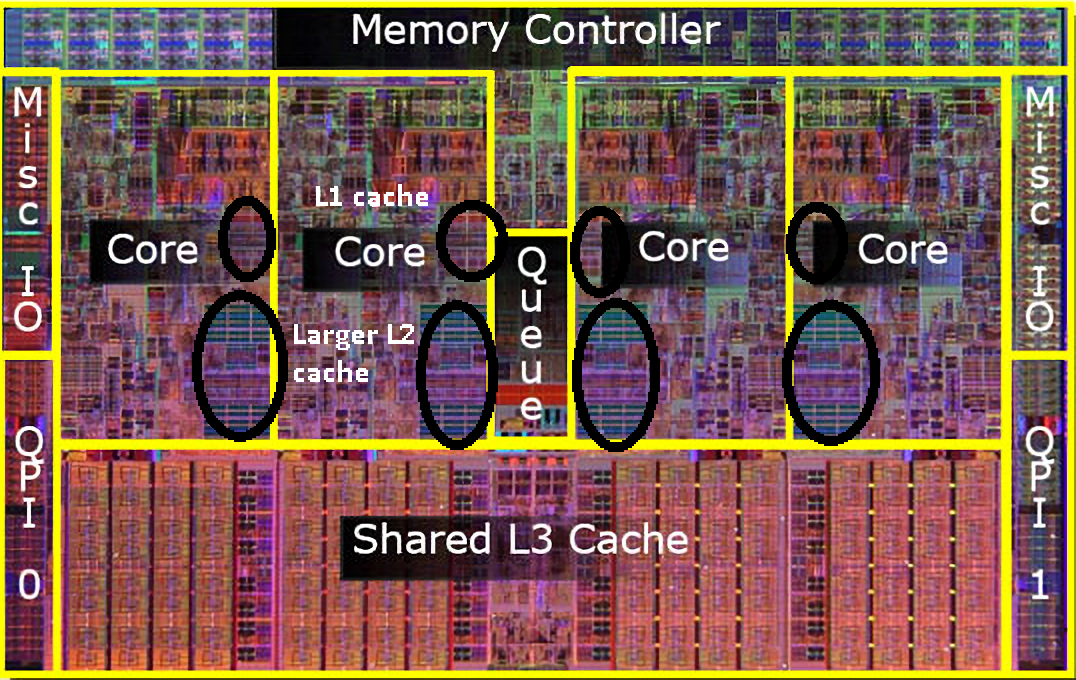
그럼 이 L1, L2, L3 캐시를 결정짓는 특징적인 부분은 무엇일까? 우선 아래 그림을 보자.
L1, L2 캐시는 코어마다 별도로 존재하고 L3캐시는 모든 코어가 공유하는 자원처럼 보이지 않는가? 실제 작동 방식도 보이는 그대로이다.
L1 캐시
L1 캐시는 코어 칩 내부에 위치하고 있고 명령어 캐시와 데이터 캐시로 나누어져 있다. 명령어 집합과 데이터 집합은 다른 특성을 보이는 경향이 있다.
명령어 집합은 똑같은 명령어가 계속 반복해서 나타날 경향이 커 주로 시간 지역성이 높고 데이터 집합은 주로 공간 지역성이 높게 나타날 가능성이 크다.
이 둘을 나누어 관리하면 서로 다른 지역성을 활용할 수 있고 별도의 파이프라인을 구축해 명령어와 데이터를 동시에 읽을 수도 있다.
이러한 장점을 취하기 위해 L1 캐시는 명령어 집합과 데이터 집합을 분리해 관리해준다. 대신, 그만큼 활용하지 못하는 공간이 생길 수 있으니 캐시 메모리 용량 측면에서는 손해이다.
L2 캐시
L2 캐시는 CPU에 따라 코어 내에 위치할 수도, 코어 밖에 위치할 수도 있다. L2 캐시를 코어 간에 공유자원으로 사용하는 경우도 있다.
일단은 L2 캐시도 코어 내에 위치한다고 가정하고 설명하자면, L1 캐시와의 유일한 차이점은 명령어 영역와 데이터 영역의 구분 없이 데이터(명령어 집합과 데이터 집합 모두)를 관리하는 것이다. 이러한 점으로 L1 캐시에 비해 불이익이 따르게 되는 것이다.
L3 캐시
L3 캐시는 코어 밖에 위치해 코어 간에 서로 공유해서 사용하는 캐시 자원이다. 캐시 메모리 중 제일 느린 영역이다.
멀티 쓰레딩
일단 우리가 하려는 일은 배열 내 모든 원소들의 합을 구하는 것이다. 멀티 쓰레딩을 활용해서 연산 속도도 개선하려 한다.
어떻게 배열을 나누어 각 코어가 하는 일을 분배해야 할까? 여러 방법이 있겠지만, 일단 두 가지만 비교하자면
- 크기가 100인 배열이 있고 코어의 개수는 2개라고 하면, 0~49번 idx의 배열과, 50~99번 idx 배열로 나누어 합 연산을 수행한다.
- 마찬가지로, 크기가 100인 배열과 코어가 2개 있다고 하면, 짝수 idx를 0번 코어에서, 홀수 idx는 1번 코어에서 처리한다.
이미 결론을 다 말한 것 같지만, 1번이 더 유리할 것이다.
L3 캐시에 올라가게 되는 데이터의 캐시 적중률은 1번이나 2번 모두 비슷할 수 있지만, L1 캐시와 L2 캐시에 올라가는 데이터의 캐시 적중률은 1번이 분명히 더 유리하다.
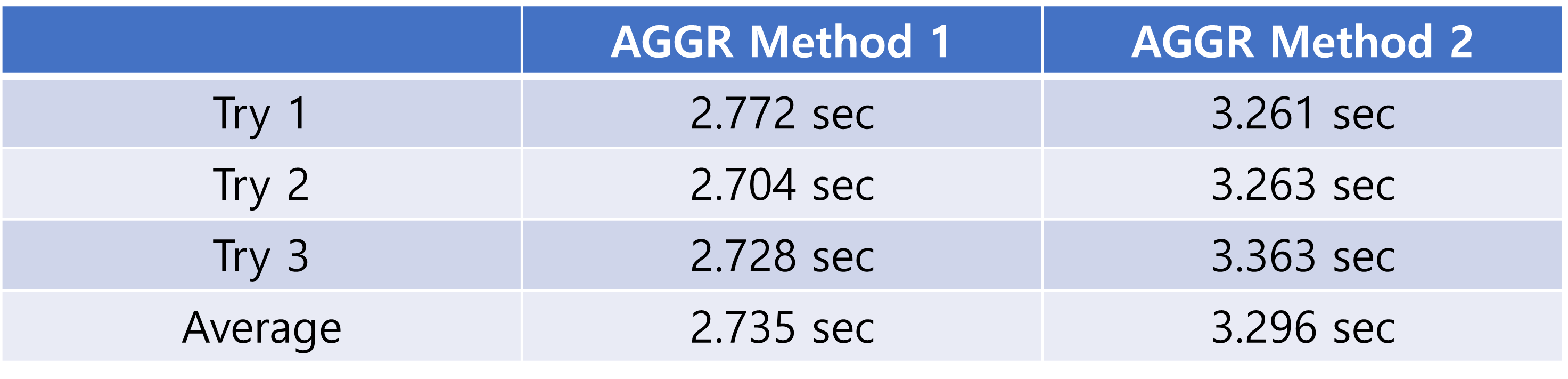
얼마나 차이가 났을까?
크다면 큰 차이이고, 작다면 작은 차이지만 17% 정도의 차이로 1번 방식이 빨랐다. 실험 결과는 아래와 같다.
- 실험 환경
- Compiler: MinGW 11.0 w64
- C17 Standard
- 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
- 4 Core, 8 Logical Processor
- L1 Cache Memory: 320KB
- L2 Cache Memory: 5.0MB
- L3 Cache Memory: 8.0MB
- RAM: 16GB
다만, 위 실험 결과는 long long 자료형을 사용하였을 때의 결과이다. 자료형을 int로만 바꾸어주어도 캐시 적중률이 거의 동일해 유의미한 속도 차이를 보여주지 않는다.
Appendix (Source Code)
Common Part
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <pthread.h>
#define ARR_SIZE 1073741824
#define NUM_THREADS 8
typedef long long dtype;
typedef struct {
const dtype *nums;
size_t step;
size_t start_idx;
size_t end_idx;
dtype sum;
} ThreadData;
void* parallel_sum(void *arg) {
ThreadData *data = (ThreadData*)arg;
data->sum = 0;
for(size_t i = data->start_idx; i < data->end_idx; i += data->step) {
data->sum += data->nums[i];
}
return NULL;
}
dtype* get_nums(const size_t arr_size) {
dtype *nums = malloc(arr_size * sizeof(dtype));
if(nums == NULL) {
perror("malloc");
exit(-1);
}
for(size_t i = 0; i < ARR_SIZE; i++) {
nums[i] = rand() % 10000;
}
return nums;
}
Method 1
int main() {
srand(time(NULL));
dtype *nums = get_nums(ARR_SIZE);
const size_t chunk_size = ARR_SIZE / NUM_THREADS;
pthread_t threads[NUM_THREADS];
ThreadData thread_data[NUM_THREADS];
for(int i = 0; i < NUM_THREADS; i++) {
thread_data[i].nums = nums;
thread_data[i].step = 1;
thread_data[i].start_idx = i * chunk_size;
thread_data[i].end_idx = (i == NUM_THREADS - 1) ? ARR_SIZE : (i + 1) * chunk_size;
thread_data[i].sum = 0;
}
const clock_t start = clock();
for(int i = 0; i < NUM_THREADS; i++) {
if(pthread_create(&threads[i], NULL, parallel_sum, &thread_data[i])) {
perror("pthread_create");
exit(-1);
}
}
dtype total_sum = 0;
for(int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
total_sum += thread_data[i].sum;
}
const clock_t end = clock();
printf("TOTAL SUM AGGR RESULT: %lld\n", total_sum);
printf("SUM AGGR EXECUTION TIME: %lf\n", (double)(end - start) / CLOCKS_PER_SEC);
free(nums);
return 0;
}
Result
Try 1
TOTAL SUM AGGR RESULT: 5040129388928
SUM AGGR EXECUTION TIME: 2.772000
Try 2
TOTAL SUM AGGR RESULT: 5040108967152
SUM AGGR EXECUTION TIME: 2.704000
Try 3
TOTAL SUM AGGR RESULT: 5040166751664
SUM AGGR EXECUTION TIME: 2.728000
Method 2
int main() {
srand(time(NULL));
dtype *nums = get_nums(ARR_SIZE);
pthread_t threads[NUM_THREADS];
ThreadData thread_data[NUM_THREADS];
for(int i = 0; i < NUM_THREADS; i++) {
thread_data[i].nums = nums;
thread_data[i].step = NUM_THREADS;
thread_data[i].start_idx = i;
thread_data[i].end_idx = ARR_SIZE;
thread_data[i].sum = 0;
}
const clock_t start = clock();
for(int i = 0; i < NUM_THREADS; i++) {
if(pthread_create(&threads[i], NULL, parallel_sum, &thread_data[i])) {
perror("pthread_create");
exit(-1);
}
}
dtype total_sum = 0;
for(int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
total_sum += thread_data[i].sum;
}
const clock_t end = clock();
printf("TOTAL SUM AGGR RESULT: %lld\n", total_sum);
printf("SUM AGGR EXECUTION TIME: %lf\n", (double)(end - start) / CLOCKS_PER_SEC);
free(nums);
return 0;
}
Result
Try 1
TOTAL SUM AGGR RESULT: 5040140662144
SUM AGGR EXECUTION TIME: 3.261000
Try 2
TOTAL SUM AGGR RESULT: 5040115655552
SUM AGGR EXECUTION TIME: 3.263000
Try 3
TOTAL SUM AGGR RESULT: 5040263545616
SUM AGGR EXECUTION TIME: 3.363000
참고 문헌
- DevLabs. (2024.08.13). “CPU 캐시란 무엇인가?” https://zpub.tistory.com/536.
- Back to Basics. (2021.09.25). “[컴퓨터구조] 시스템 캐시란? (feat. L1, L2, L3)” https://woozzang.tistory.com/155
- OpenAI. (2024). ChatGPT(Aug 8, 2024). GPT-4o. https://chat.openai.com.

댓글남기기