
numpy가 더 빠른 이유-레지스터 입장에서
numpy가 빠른 이유
부제: numpy 10배 더 빠르게 쓰기
SIMD
- Single Instruction Multi Data
- 한번의 CPU 명령어로 두개 이상의 데이터를 처리
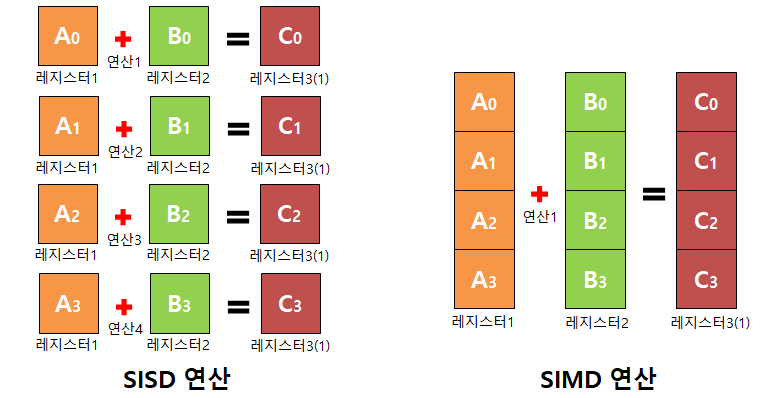
SIMD 아직은 안 알랴줌
SIMD가 그래서 뭔지 더 구체적으로 알려줘..
그치, 동시에 여러 데이터를 조상님이 처리해주진 않지
메모리에 [3, 6, 1, 7]이라는 array(행렬)이 있다고 하자. 모든 item(요소)에 3을 곱할거다. 그러면 원래는 어떻게 작동할까?
그 전에, 어떻게 구현할 것인가?
for (int i = 0; i < 4; i++) {
array[i] = array[i] * 3;
}
원래는 어떻게 작동하는데?
이제 컴퓨터구조 이야기를 해보자 메모리에는 당연히 배열이 있겠지. 프로그램에서 선언을 했으니
계산을 하기 전에 CPU 캐시에 데이터를 담을 것이다. 그리고 범용레지스터에 마지막으로 데이터를 옮긴 다음에 ALU(Arithmetic Logic Unit, 진짜로 계산하는 애)가 3을 곱해줄거고 반환값을 다시 레지스터에 담는다. 마지막으로 레지스터에 올리는 과정을 4번 반복한다.
더군다나 입력값을 레지스터에 올려야하고 곱해줄 숫자도 레지스터에 올리고 결과값도 레지스터에 올리니 1 iteration에 레지스터에 값을 3번 올려야 한다. 총 4 iteration이니 12번 하게 되는 것이다.
이제 SIMD 얘기를 시작해보자
SIMD를 사용하면?
우선, array의 item을 레지스터에 하나하나씩 올리지 않는다. 그리고 CPU에는 SIMD 연산을 위한 특수레지스터가 존재한다. 전통적으로 CPU 레지스터의 크기는 32비트이지만, SIMD를 위한 레지스터는 512비트 까지도 있다. 대표적으로 인텔의 AVX512나 ARM의 NEON이 있다.
그래서 그게 뭐 어떻다는거야?
8비트 integer를 선언했다고 해보자. AVX512에 총 64개의 데이터를 동시에 저장할 수 있는 것이다. 즉, 64개의 데이터를 레지스터에 동시에 올릴 수 있다는 것이다.
반복 연산을 얼마나 줄였나?
다시 위 예시로 가자. 원래 정석적으로 개발자가 의도한 그대로 작동을 한다면, load 4번, multiply 4번, save 4번 총 12번 레지스터를 건드린다. SIMD를 사용하면 총 3번만 건드리는 것이다. int8 자료형이 64개가 있다고 하면, 레지스터를 192번 건드리지만, SIMD를 사용하면 역시나 3번 건드린다. 데이터만 다른 똑같은 연산의 반복 회수를 64배나 줄인 것이다.
우리가 고려해야 할 점은?
C++.. SIMD를 위한 명령어 공부를 해야하는거야?!?!
C/C++ 코딩할 때, SIMD 연산을 위한 명령어를 따로 공부해야 할까? 대부분 그런 것 까지 신경쓸 필요는 없을 것이다. 대부분 컴파일러에서 SIMD 자동 최적화 즉, auto-vectorization을 지원한다.
Python은 지원하기는 해??
interpreter 언어다 보니.. 자동으로 최적화 해주기도 힘든 부분이 존재한다. 하지만 방법은 존재한다! numpy array를 사용하면 된다! numpy는 경우에 따라 CAPI를 통해 C++을 아주 적극적으로 활용하는 라이브러리다. SIMD도 당연 지원하고 instruction 별로 SIMD 최적화도 해놓았다!!
조금 더 빠르게 쓰고 싶으면?
결론적으로 하고 싶은 이야기는 8비트 자료형으로도 아주 충분할 것 같으면 int8 자료형을 사용하고, 16비트 자료형으로도 충분할 것 같으면 int16 자료형을 사용하면 빨라진다. 실험상으로, np.int8 자료형은 np.int64보다 10배 가량의 성능 개선을 보였고 python list보다는 100배 정도 더 빨랐다.
실험 코드
"""
Environment
-------------------
Apple M2
macOS Sonoma 14.3.1
Python 3.11.5
Clang 14.0.6
numpy 1.24.3
"""
import random
import numpy as np
import time
if __name__ == '__main__':
py_list = [random.randrange(1, 40) for _ in range(33554432)]
np8_arr = np.random.randint(1, 40, size=33554432, dtype=np.int8)
np16_arr = np.random.randint(1, 40, size=33554432, dtype=np.int16)
np32_arr = np.random.randint(1, 40, size=33554432, dtype=np.int32)
np64_arr = np.random.randint(1, 40, size=33554432, dtype=np.int64)
start_time = time.time()
np8_arr * 3
end_time = time.time()
print("numpy, int8 연산 시간: ", end_time - start_time)
start_time = time.time()
np16_arr * 3
end_time = time.time()
print("numpy, int16 연산 시간: ", end_time - start_time)
start_time = time.time()
np32_arr * 3
end_time = time.time()
print("numpy, int32 연산 시간: ", end_time - start_time)
start_time = time.time()
np64_arr * 3
end_time = time.time()
print("numpy, int64 연산 시간: ", end_time - start_time)
start_time = time.time()
for item in py_list:
item * 3
end_time = time.time()
print("python list 연산 시간: ", end_time - start_time)
실험 결과
numpy, int8 연산 시간: 0.004483938217163086
numpy, int16 연산 시간: 0.008640050888061523
numpy, int32 연산 시간: 0.017509937286376953
numpy, int64 연산 시간: 0.053878068923950195
python list 연산 시간: 0.5993926525115967
마지막으로 붙이는 사족
다만, 병렬로 데이터를 처리하기에 아주 적합한 환경에서 위 결과가 나오기는 했다. 논리적 순서가 필요한 연산이나 컴파일러나 numpy가 auto-vectorization하기 어려운 상황에서는 시스템 기본 int 자료형이 더 적합할 것이다.
참고문헌
- Teus. (2022.02.10). “[Python] Numpy가 빠른 이유-1편 (하드웨어 관점에서, SIMD)”. https://devocean.sk.com/blog/techBoardDetail.do?ID=163631.
- Fasoo. (2019.09.17). “SIMD (Single Instruction Multiple Data)에 대한 집중탐구!”. https://m.blog.naver.com/fs0608/221650925743.
- Intel. “인텔® Advanced Vector Extensions 512(인텔® AVX-512)를 통해 까다로운 워크로드를 위한 성능과 ROI를 극대화하십시오”. https://www.intel.co.kr/content/www/kr/ko/products/docs/accelerator-engines/what-is-intel-avx-512.html.
- Numpy. “CPU/SIMD Optimizations” https://numpy.org/doc/stable/reference/simd/index.html.
- OpenAI. (2024). ChatGPT(Jan 10, 2024). GPT-4. https://chat.openai.com.

댓글남기기