
numpy가 더 빠른 이유-캐시메모리 입장에서
numpy가 더 빠른 이유
너무 바쁜 파이선
numpy 이야기를 하기 전에, 파이선 이야기를 먼저 하고자 한다. numpy가 더 빠른 이유-레지스터 입장에서 포스트의 내용을 살펴보면 numpy int32는 python list보다 34배 넘게 더 빠르다. SIMD만 고려하면 2배 정도 차이나야 할 것 같다. (실험 컴퓨터는 ARMv8.6-A instruction set 사용, 최대 64bit)
물론 파이선 3.11 기준으로 integer 자료형의 크기는 28바이트나 된다. 경우에 따라 더 커질 수도 있다.
더럽게 무거운 놈인 것은 확실하다.
다시 제목으로 돌아가서, 왜 너무 바쁜 파이선이라는 제목을 붙였을까?
python list는 array가 아니다. 겉으로 생긴 것은 C++, JAVA, C# 배열과 비슷하지만, 내부 구조는 다르다.
C++ array(numpy array)
int arr[4] = {1, 2, 3, 4}
위와 같은 배열이 있다고 하면 위 배열은 4byte만큼의 메모리를 연속적으로 저장한다. 변수 arr은 해당 배열의 시작 주소를 가지고 있고 index를 통해 원하는 배열의 원소에 접근할 수 있다.
\[item addr = start addr + 4 * index\]python list
파이선 리스트의 저장 구조는 C++과 다르다. 파이선 리스트 object에는 ob_item이라는 이중 포인터가 있고, ob_item은 리스트 원소들의 주소 값을 저장한 C언어의 배열을 가르킨다. 그 배열은 배열 원소들의 주소를 저장하고 있으며 ob_item에 저장된 포인터를 통해 실제 원소 값에 접근한다.
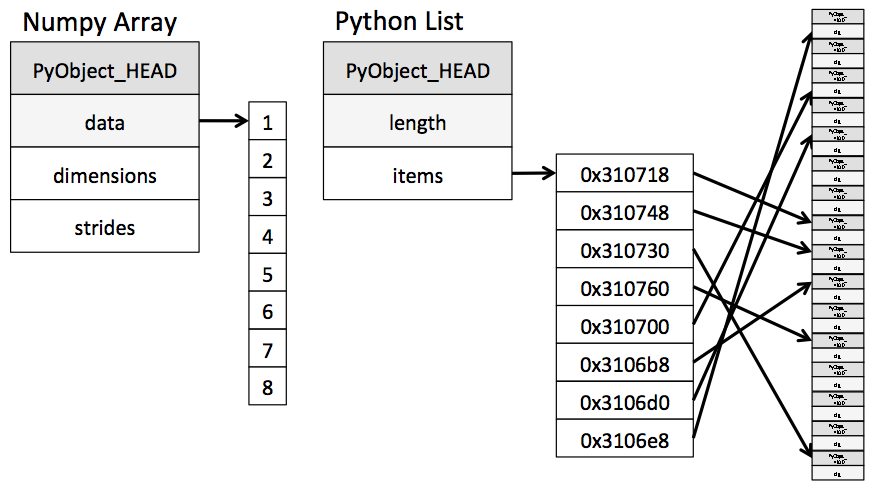
그래서 그거랑 성능이랑 무슨 연관이 있는 것인데?
C++ array를 보자. 규칙이 있다. 그것도 아주 간단한 규칙. 배열의 원소가 저장되어있는 메모리의 주소값이 정확히 4씩 증가한다.
python list는 그에 반해 규칙이 없다. ob_item이 저장하고 있는 주소를 보면 그냥 중구난방이다.
대충은 알겠는데.. 그런 규칙성이 정확히 어떤 이점이 있는건지 잘..
이때까지는 자료구조 이야기였다. C++ array의 자료구조와 python list의 자료구조를 비교해보았다.
이제 주제를 살짝 바꿔서, 컴퓨터구조 이야기를 시작해보자.
컴퓨터 메모리는 계층적으로 이루어져 있다. CPU(ALU)의 연산 속도에 비해 메모리는 턱없이 느리기 때문에 이를 그나마 완화하고자 가장 느리지만 용량이 큰 메모리, 그리고 상위 계층으로 갈수록 빠르지만 용량이 작은 메모리로 구성이 된다. 그림으로 표현하면 아래와 같다.
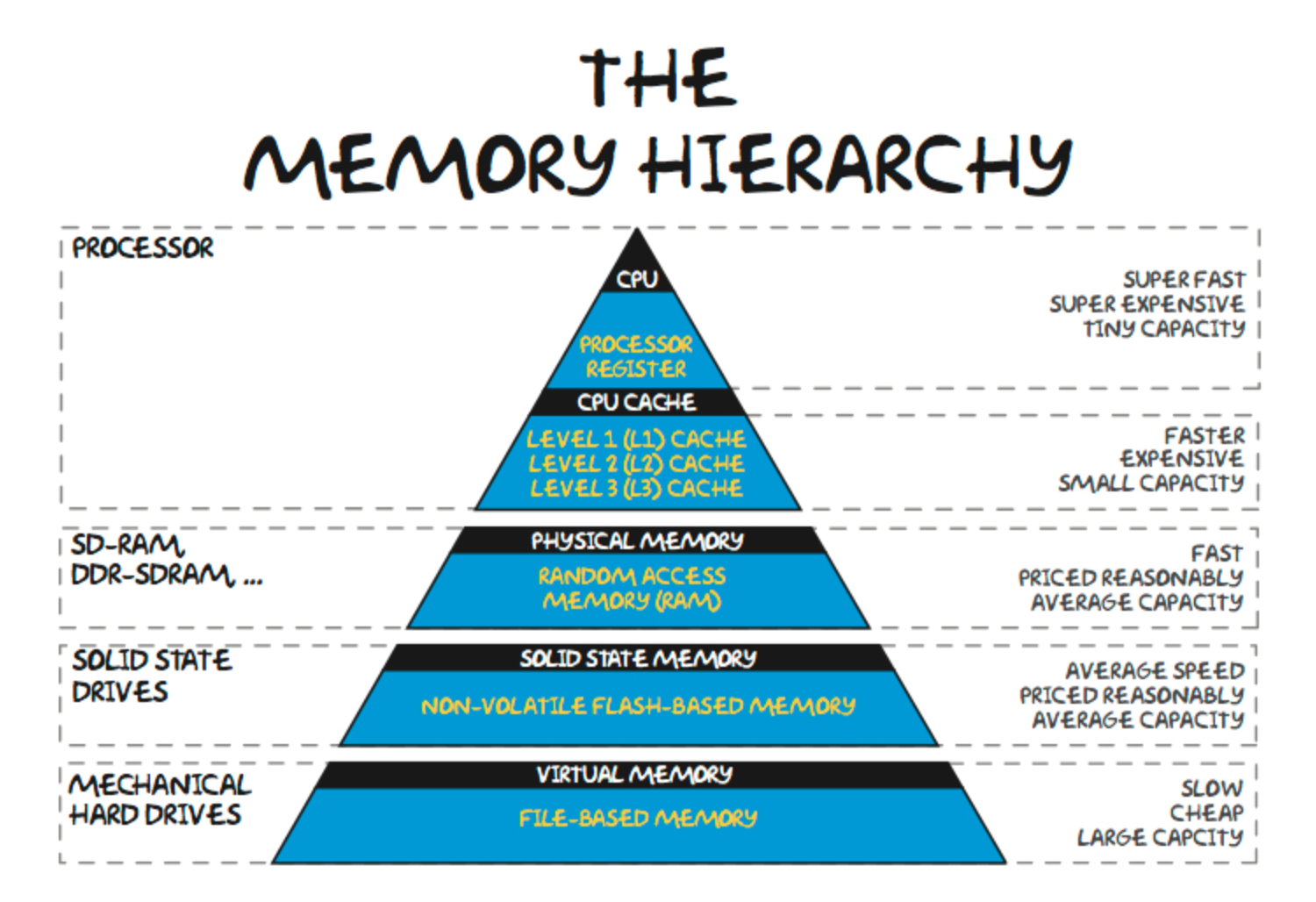
SSD가 제아무리 빨라봐야 RAM 보다는 느리고 RAM이 제아무리 빨라봐야 캐시 메모리(Cache Memory)보다 느리다. 반대로, 캐시 메모리는 제아무리 커봐야 램보다는 너무 작다.
CPU가 사용하고자 하는 데이터가 캐시에 없으면 RAM까지 가야하고 RAM에서도 없으면 SSD까지 가게 된다. 캐시 메모리도 L1, L2, L3로 나누어지게 되는데, 하위 단의 캐시 메모리일 수록(L3) 레지스터와 거리도 멀어지고 속도도 느려진다.
캐시 메모리에는 어떤 데이터를 저장하는데?
Temporal Locality
- 프로그램 실행 시 한번 접근이 이루어진 주소의 메모리 영역은 자주 접근하게 된다는 속성
- 반복적인 접근이 발생하는 데이터를 캐시 메모리에 저장
Spatial Locality
- 프로그램 실행 시 접근하는 메모리 영역은 이미 접근했던 영역의 근처일 가능성이 높다는 속성
- 인접한 주소의 데이터를 캐시 메모리에 저장
이제 결론으로
감이 올 것이다. 사실 별 내용도 없었다. 핵심은 속도가 빠른 캐시메모리에는 최근에 접근했던 영역의 주변 데이터를 같이 저장한다는 것이다.
Python list의 ob_item은 spatial locality를 충족시킨다. 하지만, 정작 우리가 원하는 정보인 ob_item에 있는 원소들은 메모리 주소가 중구난방이다. 실제 시스템 상에서는 위에 있는 python list 자료구조 그림보다 더 심할 것이다.
너무 바쁜 파이선이라는 부제를 지은 이유도 그 때문이다. PyListObject에서 ob_item에 접근하고 그 포인터를 이용해 최종 목적지에 도달하니, 그 최종 목적지마저도 위치가 다들 제각각이니 너무 바쁜 파이선이라는 이름을 지어주었다.
Appendix (Source Code)
Python
"""
Environment
---------------
Python 3.11.5
Clang 14.0.6
numpy 1.24.3
"""
import ctypes
import random
import numpy as np
if __name__ == '__main__':
lib = ctypes.CDLL('./arr_addr.so')
lib.print_arr_addr.argtypes = [ctypes.c_void_p, ctypes.c_int]
lib.print_arr_addr.restype = None
py_list = [random.randrange(1, 100) for _ in range(5)]
np_arr = np.array(py_list, dtype=np.int32)
print("-------------py_list-------------")
for item in py_list:
print("address: {:}".format(hex(id(item))), end=',\t')
print("value: {:}".format(item))
print("-------------np_arr--------------")
lib.print_arr_addr(ctypes.c_void_p(np_arr.ctypes.data), ctypes.c_int(len(np_arr)))
C++
/*
Environment
---------------
Clang 14.0.6
STD C++23
*/
#include <iostream>
using namespace std;
extern "C" {
void print_arr_addr(void *array_address, int size) {
for (int i = 0; i < size; i++) {
cout << "address: " << (int*)array_address + i << ",\t";
cout << "value: " << *((int*)array_address + i) << endl;
}
cout << endl;
}
}
Result
-------------py_list-------------
address: 0x10508a558, value: 5
address: 0x10508b078, value: 94
address: 0x10508ae38, value: 76
address: 0x10508a758, value: 21
address: 0x10508ae38, value: 76
-------------np_arr--------------
address: 0x116e1aed0, value: 5
address: 0x116e1aed4, value: 94
address: 0x116e1aed8, value: 76
address: 0x116e1aedc, value: 21
address: 0x116e1aee0, value: 76
참고문헌
- SKT Enterprise. “[Python] Numpy가 빠른 이유-2편 (PyObject와 메모리 구조 관점에서)”. https://www.sktenterprise.com/bizInsight/blogDetail/dev/2679.
- 박상원 깃헙블로그. “[Python] 리스트에서 메모리 할당에 대한 생각”. https://eprj453.github.io/python/2020/12/05/Python-리스트에서-메모리-할당에-대한-생각/.
- 항상 초심으로. “Cache Friendly Code 기법”. https://gogorchg.tistory.com/entry/Cache-Friendly-Code-기법.
- python. “cpython”. https://github.com/python/cpython.
- OpenAI. (2024). ChatGPT(Jan 10, 2024). GPT-4. https://chat.openai.com.

댓글남기기