
Logistic Regression
Logistic Regression
Fundamental Concept
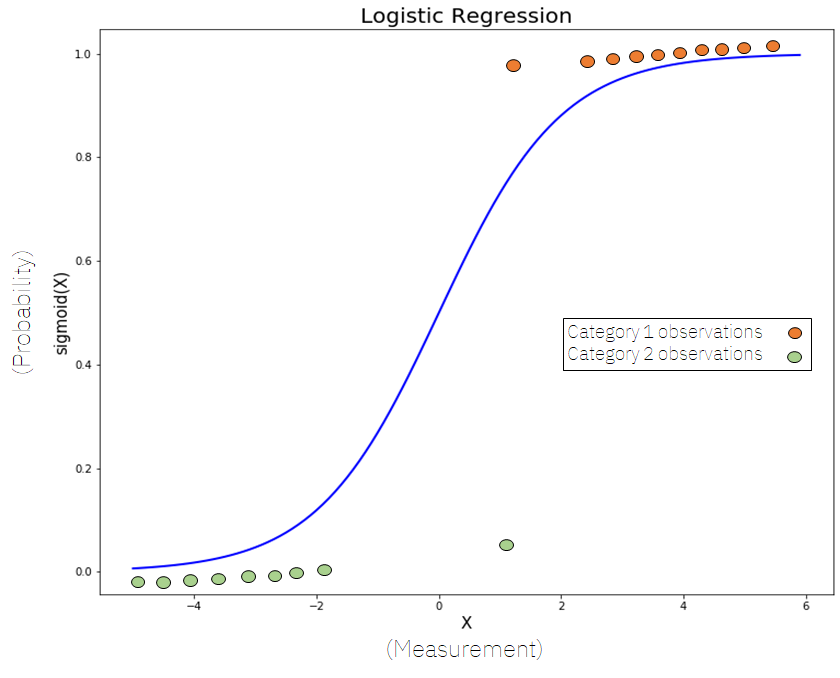
- Logistic regression is an algorithm that learns the probability of an event occurring.
- Usually, binary classification is performed, but more than three classification problems can also be dealt with.
Algorithm
- The deflection w_0 is added to the weight vector w corresponding to the data x to calculate (W^T)x + W_0.
- The same is true of learning the weight vector w and the deflection w_0 from the data.
- Unlike linear regression, the probability is calculated, so the range of output results should be between 0 and 1.
- Therefore, a value between 0 and 1 is returned using the sigmoid function.
- sigmoid function: f(z) = 1/(1+e^(-z))
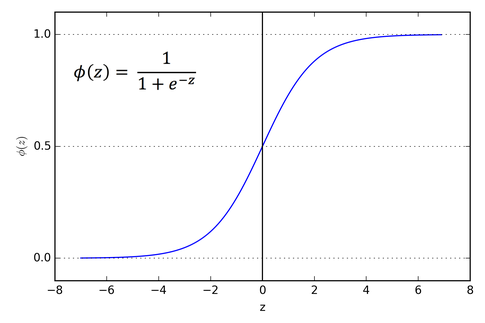
- f(z)(w^T+w_0) is calculated as a probability p in which a label corresponding to data x is y as a sigmoid function.
- Binary classification usually takes the probability of a prediction result of 0.5 as a threshold.
- When learning, the error is minimized with the loss function of logistic regression.
- Find the minimum value of the loss function value while calculating the slope of the logistic regression function value.
Sample Code
import numpy as np
from sklearn.linear_model import LogisticRegression
X_train = np.r_[np.random.normal(3, 1, size = 50),
np.random.normal(-1, 8, size = 50)].reshape((100, -1))
y_train = np.r_[np.ones(50), np.zeros(50)]
model = LogisticRegression(solver = 'lbfgs')
model.fit(X_train, y_train)
model.predict_proba([[0], [1], [2]])[:, 1]
array([0.44857149, 0.52197344, 0.59443856])
Determination boundary
- When unknown data is put into the model trained to solve the classification problem and classified, the classification result changes to a boundary of some data.
- The boundary in which the classification results change is called the determination boundary.
- In logistic regression, the decision boundary is where the result of calculated probability is 50%.
참고문헌
- 秋庭伸也 et al. 머신러닝 도감 : 그림으로 공부하는 머신러닝 알고리즘 17 / 아키바 신야, 스기야마 아세이, 데라다 마나부 [공] 지음 ; 이중민 옮김, 2019.

댓글남기기