kNN (k-Nearest Negihbors algorithm)
Fundamental Concept
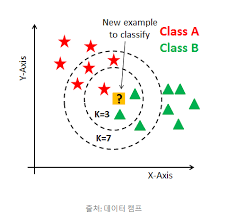
- kNN can be applied to both classification and regression problems.
- When classifying unknown data, the distance to the learning data is calculated to determine how the data is classified up to k points nearby, and then the data is classified by majority vote.2.
Algorithm
- calculating the distance of learning data from input data
- Search for k learning data close to input data
- Categorize input data that is not known by majority vote in the label of learning data.
Sample Code
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = make_moons(noise = 0.3)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
model = KNeighborsClassifier(n_neighbors = 5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test)
difference in decision boundary according to k value
- The smaller the k value, the more likely over-fitting occurs.
- Conversely, if the value of k is too large, the decision boundary cannot be accurately learned.
points to note
- The kNN is basically not suitable for large amounts of data processing.
- High-level data is difficult to learn. This is because asymptotic assumptions of the kNN algorithm are not necessarily established in high-dimensional data.
참고문헌
- 秋庭伸也 et al. 머신러닝 도감 : 그림으로 공부하는 머신러닝 알고리즘 17 / 아키바 신야, 스기야마 아세이, 데라다 마나부 [공] 지음 ; 이중민 옮김, 2019.


댓글남기기