
✨️Going Beyond Local: Global Graph-Enhanced Personalized News Recommendation
✨️Going Beyond Local: Global Graph-Enhanced Personalized News Recommendation
논문 정보
- Boming Yang, Dairui Liu, Toyotaro Suzumura, Ruihai Dong, Irene Li
- RecSys’23: Proceedings of the 17th ACM Conference on Recommender Systems
- 2023
Introduction
Goal & Task
- Personalized News Recommendation System 구현
-
개인화 뉴스 추천 시스템 구현
- MIND(MIcrosoft News Dataset) 사용
- 유저의 클릭 히스토리
- 유저 수: 1,000,000
- 클릭 히스토리에 해당하는 뉴스
- 뉴스 수: 161,013
- 총 클릭 로그 개수
- 클릭 수: 24,155,470
- 유저의 클릭 히스토리
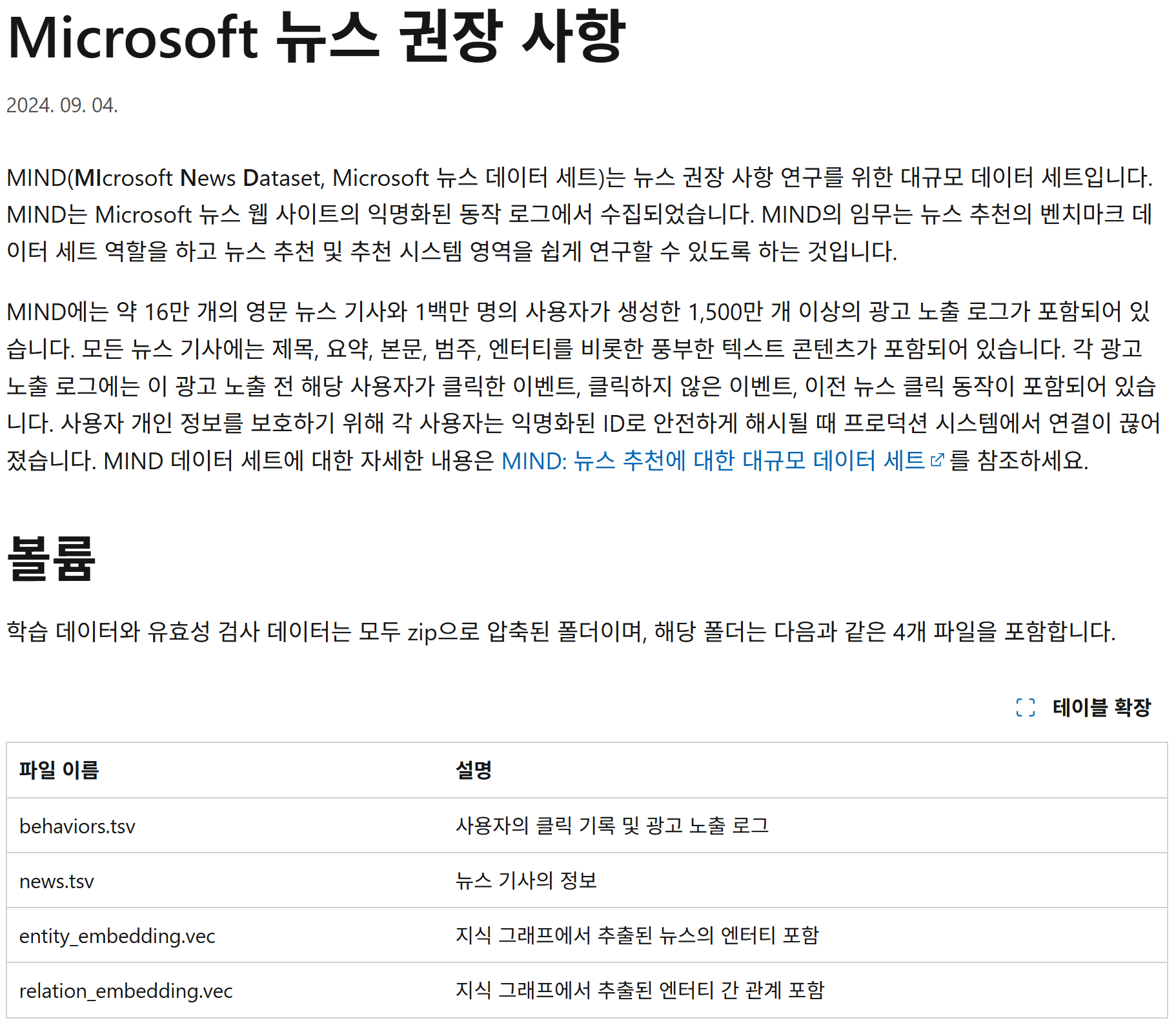
- 데이터셋의 구체적 스키마는 아래 링크 참조
기존 시스템의 문제점
- 뉴스 추천(News Recommendation)은 사용자의 관심사에 맞는 뉴스를 제공하는 작업
- 뉴스 도메인은 다른 추천 분야보다 더 변화가 빠름
- 기존에는 주로 콘텐츠 기반(Content-based) 방식 사용
- 사용자가 읽은 뉴스의 콘텐츠로부터 사용자의 관심사 모델링
- 후보 뉴스 콘텐츠와 비교하여 추천 수행
- 많은 연구들이 딥러닝 + NLP 기술을 통해 뉴스의 제목 및 내용에서 의미를 추출
제안모델, GLORY: Global-LOcal news Recommendation sYstem
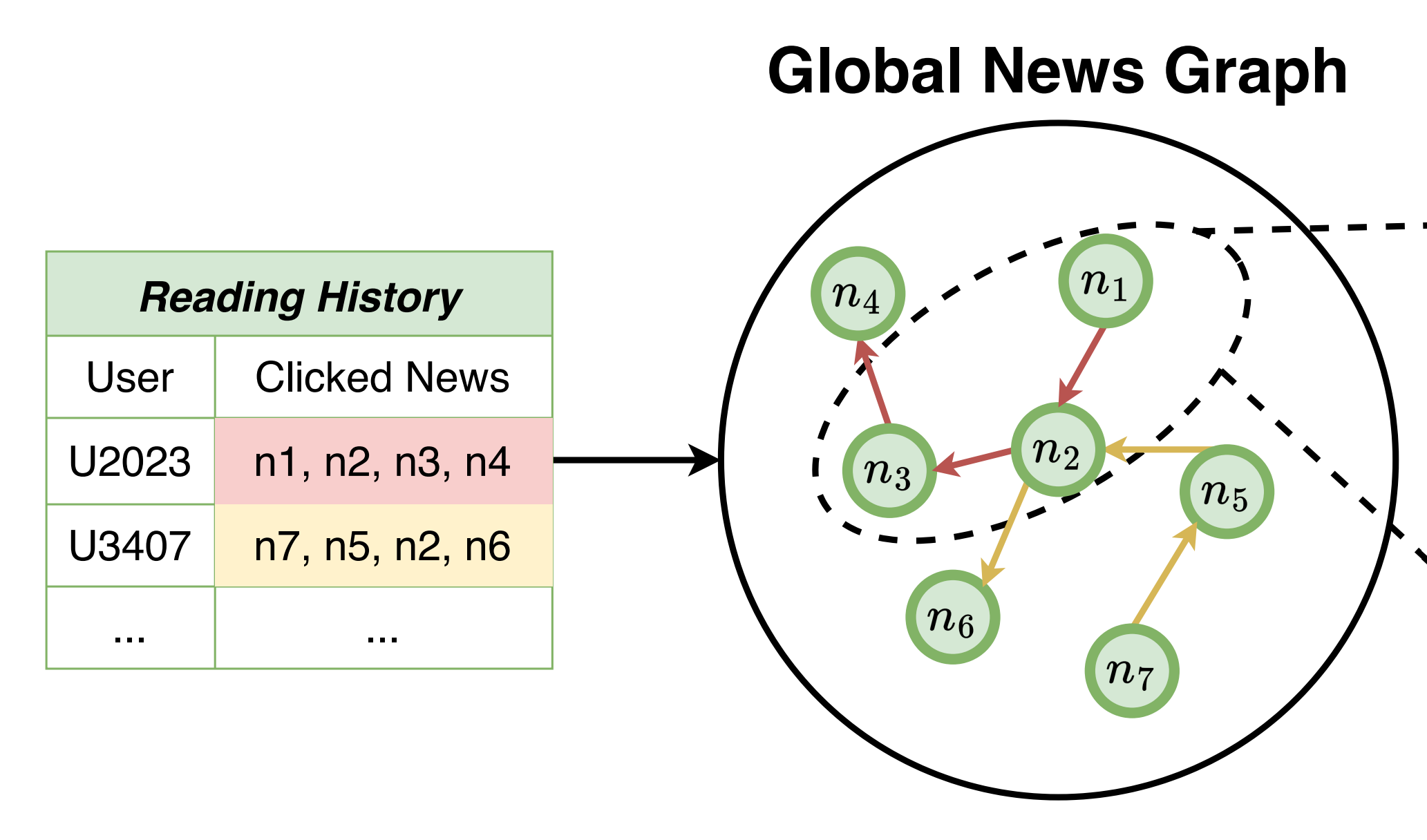
Global News Graph
- 사용자 개인의 local history로 그래프 생성
- 글로벌 정보 global graph-based behaviors로 그래프 생성
-
두 그래프를 결합하여 뉴스 콘텐츠에 대한 풍부하고 다양성 높은 표현을 학습
- 빨간색 에지: U2023 유저의 클릭 순서에 따른 그래프 생성
-
노란색 에지: U3407 유저의 클릭 순서에 따른 그래프 생성
- 각 유저의 local graph를 결합하여 global graph 생성
Content-based vs. Collaborative Filtering
- Content-based 방식은 새로운 카테고리, 장르의 아이템을 추천해주기 어렵다는 한계점을 지님
- 개별 유저의 열람 기록에만 의존하여 임베딩을 생성하기 때문
- 한편, Collaborative Filtering 방식은 나와 비슷한 유저가 열람한 아이템을 추천해줄 수 있음
- 나와 비슷한 유저가 이것을 클릭(혹은 구매, 열람, 등…)했는데, 너는 관심 없어?
- 나와 비슷한 유저가 다른 장르의 아이템을 열람한 경우, 이를 추천해줄 수 있음
- 제안 시스템의 Global News Graph는 이러한 Content-based 방식의 한계점을 돌파하고자 하는 시도로도 해석될 수 있어 보임
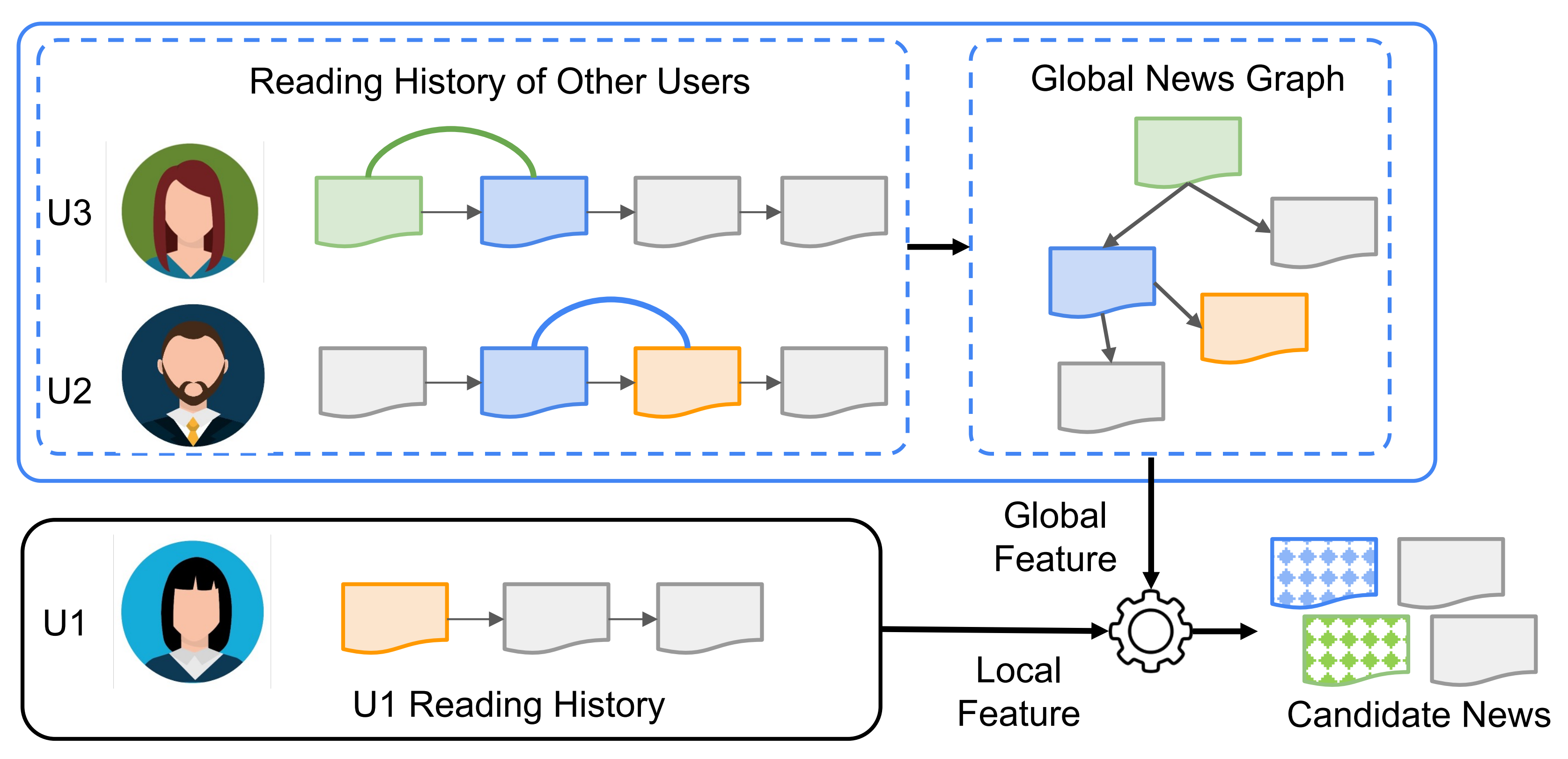
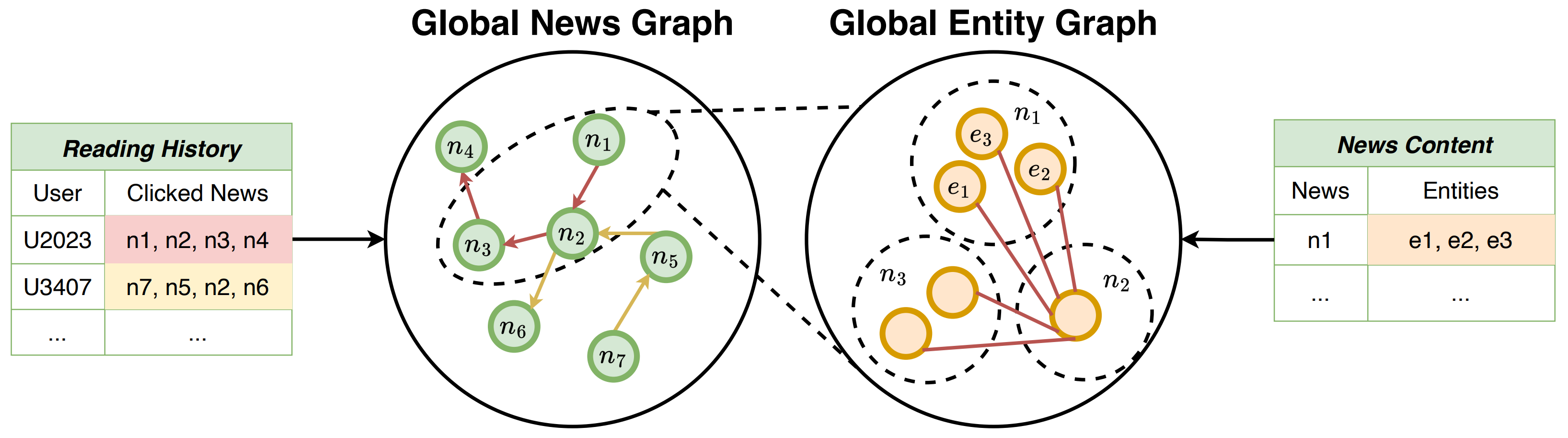
Global Entity Graph
- 위 그림에서
- 사용자 개인의 뉴스 취향을 개별적으로 고려하는 경우
-
U1 유저에게 초록색, 파란색 뉴스를 추천하지 못하는 경우가 발생할 수 있음
-
엔티티 그래프는 유저의 클릭 기록 그래프를 바탕으로 생성
- Global News Graph에서 n1, n2, n3 뉴스 노드가 연결되어 있음을 알 수 있음
- 특히 n2 뉴스 노드는 n1 노드와 n3 노드와 연결되어 있음
-
이때, n2 뉴스에 등장하는 엔티티와 n1과 n3 뉴스에 등장하는 엔티티 간에 에지를 생성
- 이를 통해, 어떠한 엔티티가 등장하는 뉴스를 열람한 후에는 어떤 엔티티가 등장하는 뉴스를 열람하는지에 대한 정보 추출
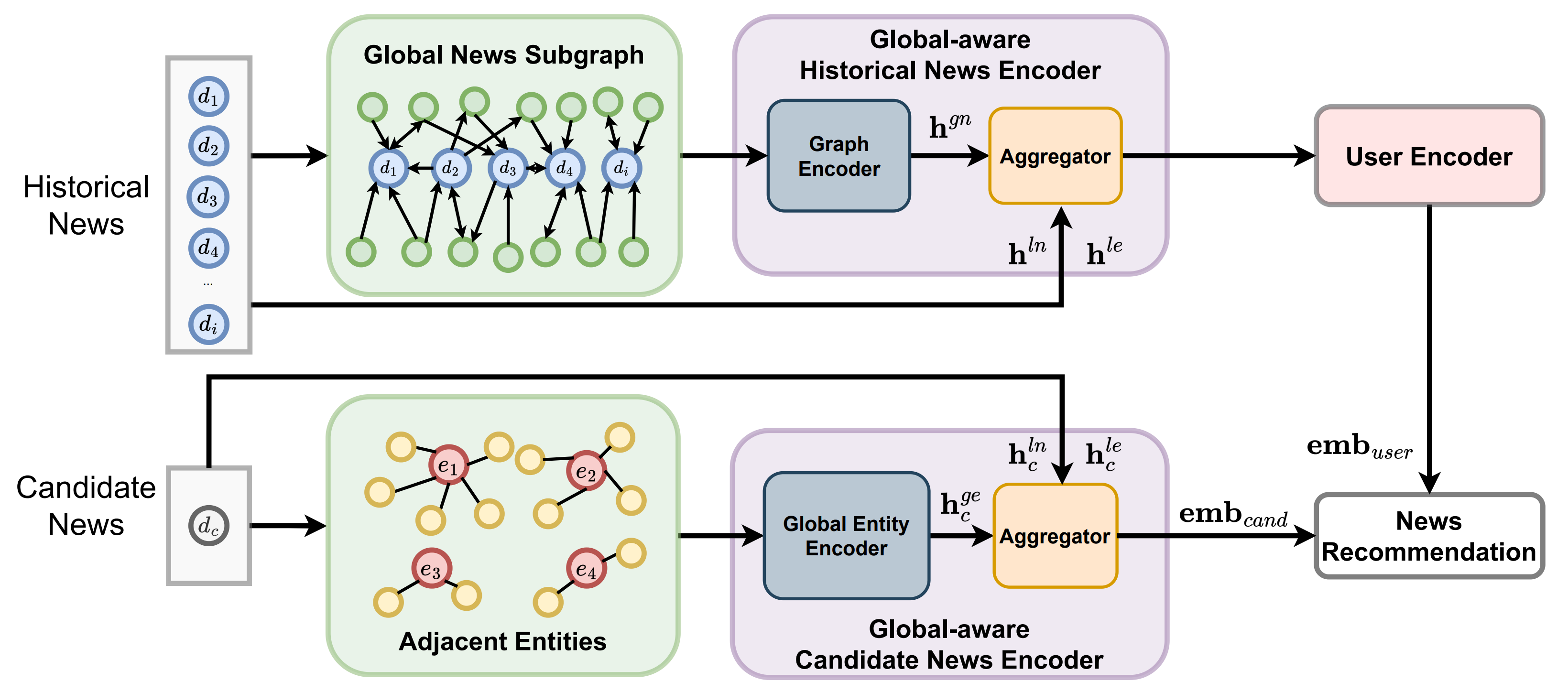
Model Architecture
- Global-aware Historical News Encoder
- MSN 전 사용자가 읽은 뉴스로부터 구축한 글로벌 뉴스 그래프 활용
- Gate Graph Neural Network (GGNN)으로 뉴스 간 관계 학습
- 사용자의 click history를 반영한 그래프를 GGNN으로 학습함으로써, 더욱 풍부한 클릭 히스토리 데이터 생성, 이를 - 학습하여 News Representation Vector 생성
- Global Candidate News Encoder
- 추천 후보 뉴스에 대해서도 글로벌 엔티티 그래프를 기반으로 표현 강화
- 글로벌 문맥을 반영하여 후보 뉴스 임베딩 생성
- Aggregator
- 위에서 얻은 Historical News Embedding과 Candidate News Embedding을 통합하여 최종 News Representation 생성
Related Work
Feature-based News Recommendation (특징 기반 뉴스 추천)
- 기본 개념
- 과거 사용자와 뉴스 간의 상호작용 데이터를 바탕으로, 뉴스 또는 사용자에 대한 feature를 추출, 이를 기반으로 추천 수행
- 대표 기법
- LibFM (Steffen R., ACM TIST, 2012)
- FM(Factorization Machine)을 활용하여 뉴스의 잠재 feature를 학습
- 뉴스의 잠재 feature를 활용하여 추천 수행
- DeepFM (Huifeng. G., et.al., arXiv preprint, 2017)
- FM 컴포넌트와 ANN(Artificial Neural Network)를 결합
- 이를 통해 비선형적 관계까지 포착
- LibFM (Steffen R., ACM TIST, 2012)
- 한계점
- 뉴스는 짧은 수명과 높은 변동성을 지님
- 후보 뉴스가 상호작용 기록이 부족하거나 전혀 없는 경우가 많음
- 이러한 경우, 충분한 feature 학습이 어려워 추천 성능이 떨어짐
Neural News Recommendation (신경망 기반 뉴스 추천)
- NAML (Chuhan Wu, et.al., arXiv preprint, 2019)
- CNN + GRU
- News Representation은 CNN으로 학습, User Representation은 GRU로 학습
- NRMS (Chuhan Wu, et.al., EMNLP, 2019)
- MHSA (Multi-Head Self-Attention)
- News Representation과 User Representation 모두 MHSA 사용
- HieRec (Tao Qi, et.al., ACL, 2021)
- Hierarchical Attention
- 3단계 구조로 뉴스의 토픽-서브토픽 기반 사용자 표현 학습
- MINER (Jian Li, et.al., ACL, 2022)
- Poly Attention + Disagreement Regularization
- 서로 다른 관심사 표현을 위한 다중 어텐션 및 불일치 정규화(disagreement regularization) 기법 사용
Graph-based News Recommendation (그래프 기반 뉴스 추천)
- GERL (Suyu Ge, et.al., WWW, 2020)
- 뉴스 제목과 주제에서 텍스트 기반 표현 학습 + 사용자-뉴스 그래프에서 그래프 기반 표현 학습 결합
- GNewsRec (Linmei Hu, et.al., Information Processing & Management, 2020)
- 이질적 사용자-뉴스-토픽 그래프를 사용해 장기 사용자 관심사 모델링
- User-as-Graph (Chuhan Wu, et.al., SIGKDD, 19)
- 사용자의 클릭 기록으로 구성된 로컬 뉴스 그래프 구성
- 이질적 그래프 풀링 방식으로 표현 집계
- DIGAT (Zhiming Mao, et.al., arXiv preprint)
- 의미적으로 관련된 뉴스 간 관계를 활용해 시맨틱 증강 그래프(Semantic Augmentation Graph) 생성
- 후보 뉴스 표현 강화
Proposing Method: GLORY
GLORY 모델 개요
- Local-level Representation Learning
- 뉴스 텍스트 및 뉴스 내 엔티티로부터 기본적인 표현 학습
- 기존 콘텐츠 기반 방법처럼 개별 뉴스의 정보만을 사용하여 벡터 표현을 생성
- 개별 뉴스의 제목 텍스트와 엔티티 임베딩 활용
- Global-aware Historical News Encoder
- 사용자가 과거에 읽은 뉴스들을 더 잘 표현하기 위해 글로벌 뉴스 그래프를 활용
- 목표
- 단순히 클릭 이력(news1, news2, …)을 나열하는 것이 아니라
- 이 뉴스들이 글로벌 맥락에서 어떻게 연결되는지를 고려하여 표현을 보강
- Local-level Representation Learning에서 생성한 news representation이 Global News Graph의 노드 피쳐 벡터
- Global News Graph의 각 노드 임베딩을 GGNN을 활용하여 보강
- Global-aware Candidate News Encoder
- 추천 후보 뉴스에 대해서도, 단순한 텍스트 기반 표현이 아니라
- 글로벌 개체 그래프(Global Entity Graph)를 사용해 의미를 확장
- 뉴스 속 등장하는 개체들(entity) 간의 관계를 통해 해당 뉴스가 어떤 글로벌 주제 및 사건과 연결되어 있는지를 학습
- User Encoder + News Recommendation Componenet
- 위 과정을 통해 얻은 히스토리 뉴스 표현 + 후보 뉴스 표현을 활용해 간단한 사용자 인코더(User Encoder)로 사용자 벡터를 구성
- 최종적으로, 사용자 벡터와 후보 뉴스 벡터 사이의 내적(dot product) 등을 통해 추천 점수를 계산
Problem Formulation (Input)
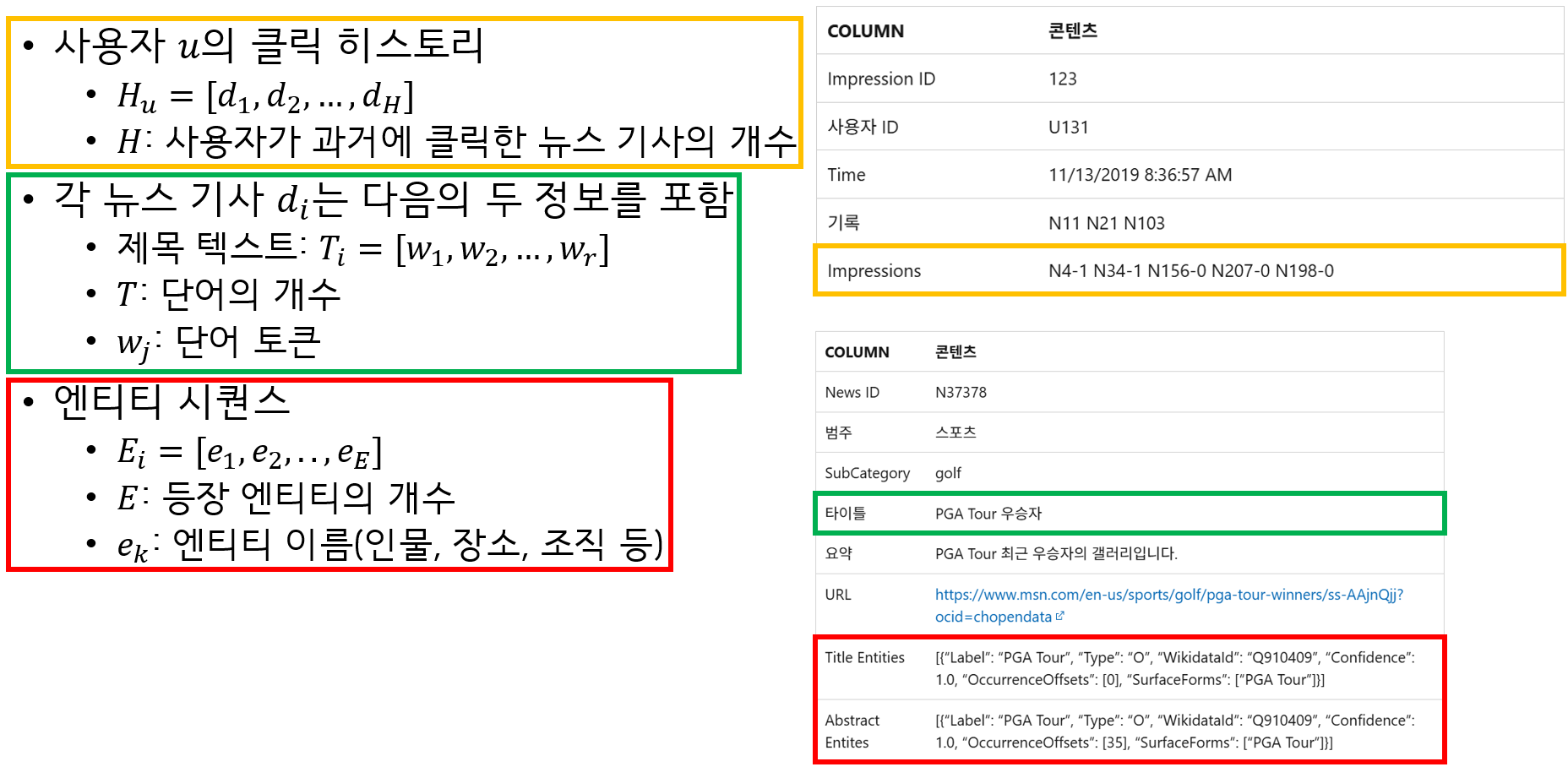
Problem Formulation (Output)
- 목표 (모델이 예측하고자 하는 것)
- 주어진 사용자 $u$와 후보 뉴스 기사 $d_c$에 대해
- 사용자 $u$가 $d_c$를 클릭할 확률 또는 관심도 점수 $s_{(u,c)}$를 예측
- $s_{(u,c)}$: 클릭할 확률 또는 선호도 점수
News Encoder, Local-aware
Local Representation (각 뉴스에 대한 representation)
- 로컬 뉴스 표현 (Local News Representation, $h_{ln}$)
- 뉴스 제목(텍스트)를 기반으로 학습
- 로컬 엔티티 표현 (Local Entity Representation, $h_{le}$)
- 뉴스에 등장하는 엔티티(개체)를 기반으로 학습
- 이때, 사용자 클릭 이력 중 최신 $L_{his}$개 뉴스만 고려하여 학습
- 또한, 뉴스 제목도 앞부분 $L_{title}$단어로 잘라 입력
Local News Representation
- Word Embedding
- 뉴스 제목 단어 시퀀스 \(T_i=[W_1, W_2, ..., W_T]\)
- GloVe 사전 학습 임베딩으로 변환 \(x_n=[x_1^w, x_2^w, ..., x_T^w]\)
- Text Multi-Head Self-Attention (MSA)
- 단어 간 관계를 파악하기 위해 Multi-Head Self-Attention 적용 \(head_i = Att(x_nW_i^Q, x_nW_i^K, x_nW_i^V)\) \(X_n=MSA(x_n)=Concat(haed_1, ..., head_h) \cdot W_o\)
- Text Attention Aggregation
- 단어 수준 표현 $X_n$을 가중합하여 로컬 뉴스 표현 $h_{ln}$ 생성 \(a_i^w=\frac{exp(q_w^{\mathsf{T}}tanh(W_wX_i^w))}{\sum_{j=1}^{T}exp(q_w^{\mathsf{T}}tanh(W_wX_j^w))}\) \(h_{ln}=\sum_{i=1}^{T}a_i^wx_i^w\)
Local Entity Representation
- Entity Embedding
- 뉴스에 등장하는 엔티티 시퀀스: \(E_i=[e_1, .., e_E]\)
- WikiKG 기반 TransE 사전학습 임베딩으로 변환 \(x_e=[X_1^e, ..., x_E^e]\)
- Entity Self-Attention
- 엔티티 간 관계를 학습 \(X_e=MSA(x_e)\)
- Entity Attention Aggregation
- 여러 엔티티 표현을 가중합해 로컬 뉴스 엔티티 표현 $h_{le}$ 생성 \(a_i^w=\frac{exp(q_w^{\mathsf{T}}tanh(W_wX_i^e))}{\sum_{j=1}^{E}exp(q_w^{\mathsf{T}}tanh(W_wX_j^w))}\) \(h_{le}=\sum_{i=1}^{E}a_i^ex_i^e\)
News Encoder, Global-aware
- Global News Graph: $G_n=(V_n,E_n)$
- $V_n$: 뉴스 기사 노드
- $E_n$: 뉴스 기사 간의 간선
- 구성 방식
- 각 사용자의 클릭 시퀀스에서 인접한 뉴스 쌍을 수집
- 예: 사용자가 $v_i$를 읽고 곧바로 $v_j$를 읽었다면, directed edge $(v_i,v_j)$를 추가
- 간선의 가중치는 해당 순서쌍이 등장한 빈도수
- 각 사용자의 클릭 시퀀스에서 인접한 뉴스 쌍을 수집
- 목표: 사용자 u의 히스토리 $H_u$를 글로벌 시각에서 보강
- 처리 과정
- 사용자 히스토리의 각 뉴스 $d_k$에 대해
- 전역 뉴스 그래프에서 k-hop 이웃 노드 샘플링
- 추출한 k-hop 이웃 노드로부터 서브그래프 $G_u^{sub}=(V_u^{sub}, E_u^{sub})$ 구성
- 각 노드에 대해 Gated Graph Neural Network (GGNN) 적용
- 초기 입력은 로컬 뉴스 표현
\(h^{(0)}=h_{ln}\) - GNN 업데이트는 아래와 같음
\(m_i^{(l+1)}=\sum_{j \in N(i)} W_g \cdot h_j^{(l)}\)
\(h_i^{(l+1)}=GRU(m_i^{(l+1)}, h_i^{(l)})\)
- 초기 입력은 로컬 뉴스 표현
- 최종 출력은 글로벌 뉴스 표현 $h_{gn}$
- 사용자 히스토리의 각 뉴스 $d_k$에 대해
News Encoder, Aggregator
- 각 히스토리 뉴스 $n_k$는 다음 세 표현을 가짐
- $h_{ln}$: 로컬 뉴스 표현 (Local News Representation)
- $h_{le}$: 로컬 엔티티 표현 (Local Entity Representation)
- $h_{gn}$: 글로벌 뉴스 표현 (Global News Representation)
- 이를 하나로 통합하기 위해 Attention Pooling 사용
- $h_k = [h_{ln};h_{le};h_{gn}]$
- $a_i^h=\frac{exp(q_h^{\mathsf{T}}tanh(W_hh_i^k))}{\sum_{j=1}^{3}exp(q_h^{\mathsf{T}})}$
User Encoder, Local-aware
- 입력: 사용자 $u$의 히스토리 $H_u$에 속한 각 뉴스에 대해 앞에서 얻은 뉴스 표현 $n_k$를 입력으로 사용
- 처리 구조
- Multi-Head Self-Attention
- 히스토리 뉴스들 간의 상호작용과 중요도 학습
- 각 뉴스 표현 $n_k$들을 서로 비교하면서 문맥 반영
- Attention Pooling Layer
- 단일 사용자 벡터 $emb_{user}$를 생성하기 위해 각 뉴스 표현에 대해 가중합 수행
- $emb_{user}=\sum_k a_k \cdot n_k$
- $a_k=\frac{\sum_{j} exp(\mathsf{T}tanh(W \cdot n_j))}{exp(q^\mathsf{T}tanh(W \cdot n_k))}$
- 이 구조는 NRMS 모델의 사용자 인코더 구조와 동일
- 각 히스토리 뉴스가 사용자 선호 표현에 얼마나 중요한지 attention score 계산
- 여러 뉴스 표현들을 집계하여 최종 사용자 벡터 생성
- Multi-Head Self-Attention
Candidate News Encoder, Global-aware
Graph Construction
- Global News Graph: $G_e=(V_e,E_e)$
- $V_e$: 엔티티 노드
- $E_e$: 엔티티 간의 간선
- 구성 방식
- 사용자의 뉴스 클릭 시퀀스에서 인접 뉴스들의 엔티티 추출
- 뉴스 간 순서를 기준으로 앞 뉴스 엔티티 -> 다음 뉴스의 엔티티
- undirected edge $(v_i,v_j)$ 생성
- 엣지 가중치: 해당 엔티티 쌍이 클릭 시퀀스에 등장한 빈도수
Global Entity Graph Encoder
- 엔티티 수가 적고 연결이 촘촘하기 때문에, 서브그래프 대신 인접 엔티티만 직접 선택
- 각 후보 뉴스에 등장하는 모든 엔티티에 대해
- 이웃 엔티티 상위 $M_e$개 선택 (엣지 가중치 기준)
- 표현 학습 단계
- 선택된 엔티티 임베딩 로드: TransE 사전학습 임베딩 로드
- Multi-Head Self-Attention (MSA) 적용
- Attention Pooling으로 글로벅 엔티티 표현 $h_{e,c}^g$ 생성
Candidate News Aggregator
- 후보 뉴스는 아래 3가지 표현을 포함
- $h_{n,c}^l$: 로컬 뉴스 표현
- $h_{e,c}^l$: 로컬 엔티티 표현
- $h_{e,c}^g$: 글로벌 엔티티 표현
- 이들을 attention 기반으로 통합하여 최종 후보 뉴스 벡터 생성
- $h_c=[h_{n,c}^l;h_{e,c}^l;h_{e,c}^g] = emb_{cand}$
User Encoder, Local-aware
- NRMS와 동일한 방식으로 User Representation Vector 생성
- C. Wu, et.al., “Neural News Recommendation with Multi-Head Self-Attention”, EMNLP, 2019
- 사용자 클릭 이력(history)에서 각 뉴스 임베딩 $n_k$ 로드
- 각 뉴스 임베딩 $n_k$에 대해 Multi-Head Attention Pooling을 적용하여 뉴스 표현 변환 및 가중합
- 최종적으로 $emb_{user}$ 생성
News Recommendation
- 훈련 방식: Negative Sampling
- 각 학습 샘플에서
- 1개 클릭된 뉴스: 양성 샘플 $n_i^+$
- K개 클리되지 않은 뉴스: 음성 샘플 ${n_i^1,…,n_i^{K_{neg}}}$
- 각 학습 샘플에서
- 점수 계산
- 사용자 임베딩 $emb_{user}$ 와
- 후보 뉴스 임베딩 $emb_{cand}$ 간 내적으로 클릭 확률 추정
- $\hat{y}i=softmax(emb{user} \cdot emb_{cand})$
- 최적화: NCE (Noise-Cantrastive Estimation) Loss
- 양성 샘플이 다른 음성 샘플보다 점수가 높도록 유도
- $L_{NCE}=-\sum_i log(\frac{exp(\hat{y}i^+)}{exp(\hat{y}_i^+)+\sum{j=1}^{K_{neg}}exp(\hat{y}_i^j)})$
- 양성 샘플이 다른 음성 샘플보다 점수가 높도록 유도
Experimental Setup
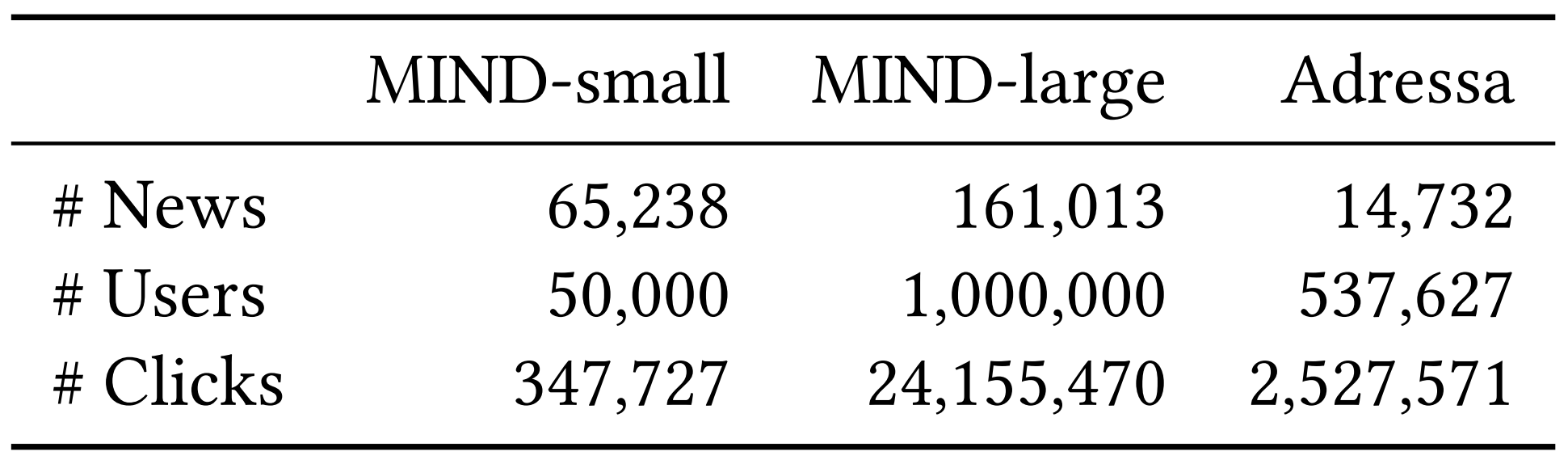
Datasets
- MSN 뉴스에서 제공하는 MIND(MIcrosoft News Dataset)
- Adresseavisen에서 제공하는 Adressa
Evaluation Metrics
- AUC (Area Under the Curve)
- MRR (Mean Reciporical Rank)
- nDCG (n Discounted Cumulative Gain)
Baselines
- Factorization Machine 기반
- LibFM
- Steffen Rendle, et.al., “Factorization machines with libfm”, ACM Transactions on Intelligent Systems and Technology (TIST), 2012
- DeepFM
- HuiFeng Guo, et.al., “DeepFM: a factorization-machine based neural network for CTR prediction”, arXiv preprint arXiv:1703.04247, 2017
- LibFM
- 인공 신경망 기반
- DKN
- Hongwei Wang, et.al., “Deep Knowledge-Aware Network for News Recommendation”, In Proceedings of the 2018 World Wide Web Conference (WWW ’18), 2018
- NPA
- Chuhan Wu, et.al., “NPA: Neural News Recommendation with Personalized Attention”, In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19), 2019
- NAML
- Chuhan Wu, et.al., “Neural News Recommendation with Attentive Multi-View Learning”, arXiv:arXiv:1907.05576, 2019
- LSTUR
- Mingxiao An, et.al., “Neural news recommendation with long-and short-term user representations”, In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
- NRMS
- Chuhan Wu, et.al., “Neural News Recommendation with Multi-Head Self-Attention”, In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019
- FIM
- Heyuan Wang, et.al., “Fine-grained interest matching for neural news recommendation”, . In Proceedings of the 58th annual meeting of the association for computational linguistics, 2020
- HieRec
- Tao Qi, et.al., “HieRec: Hierarchical User Interest Modeling for Personalized News Recommendation”, In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021
- MINER
- Jian Li, et.al., “MINER: Multi-Interest Matching Network for News Recommendation”, In Findings of the Association for Computational Linguistics: ACL 2022., 2022
- DKN
Experiment Settings
Data Preprocessing + on-the-fly Sampling Parameter
- 가장 최근 $L_{his}=50$개 뉴스의 유저 히스토리 사용
- 뉴스 기사 제목 최대 길이: $L_{title}=30$
- 각 뉴스의 최대 엔티티 개수: $L_{entity}=5$
- 비 클릭 뉴스 샘플링 개수: $K_{neg}=4$
- Global News Graph 샘플링 이웃 노드 개수: $M_n=8$
- Global News Graph 샘플링 홉 수: $K_n=2$
- Global Entity Graph 샘플링 이웃 노드 개수: $M_e=10$
- Global Entity Graph 샘플링 홉 수: $K_e=1$
Text Embedding dimensions
- News Word Text: 300-dimensional GloVe word embeddings
- Entity Embedding: 100-dimensional TransE entity embeddings
Model Construction
- # of GGNN layers: 3
- News Representation Dimension: 400
Model Training
- Adam Optimizer
- learning rate: $2e^{-4}$
- linearly decayed with 10% warm-up steps
Results
Main Result (MIND)
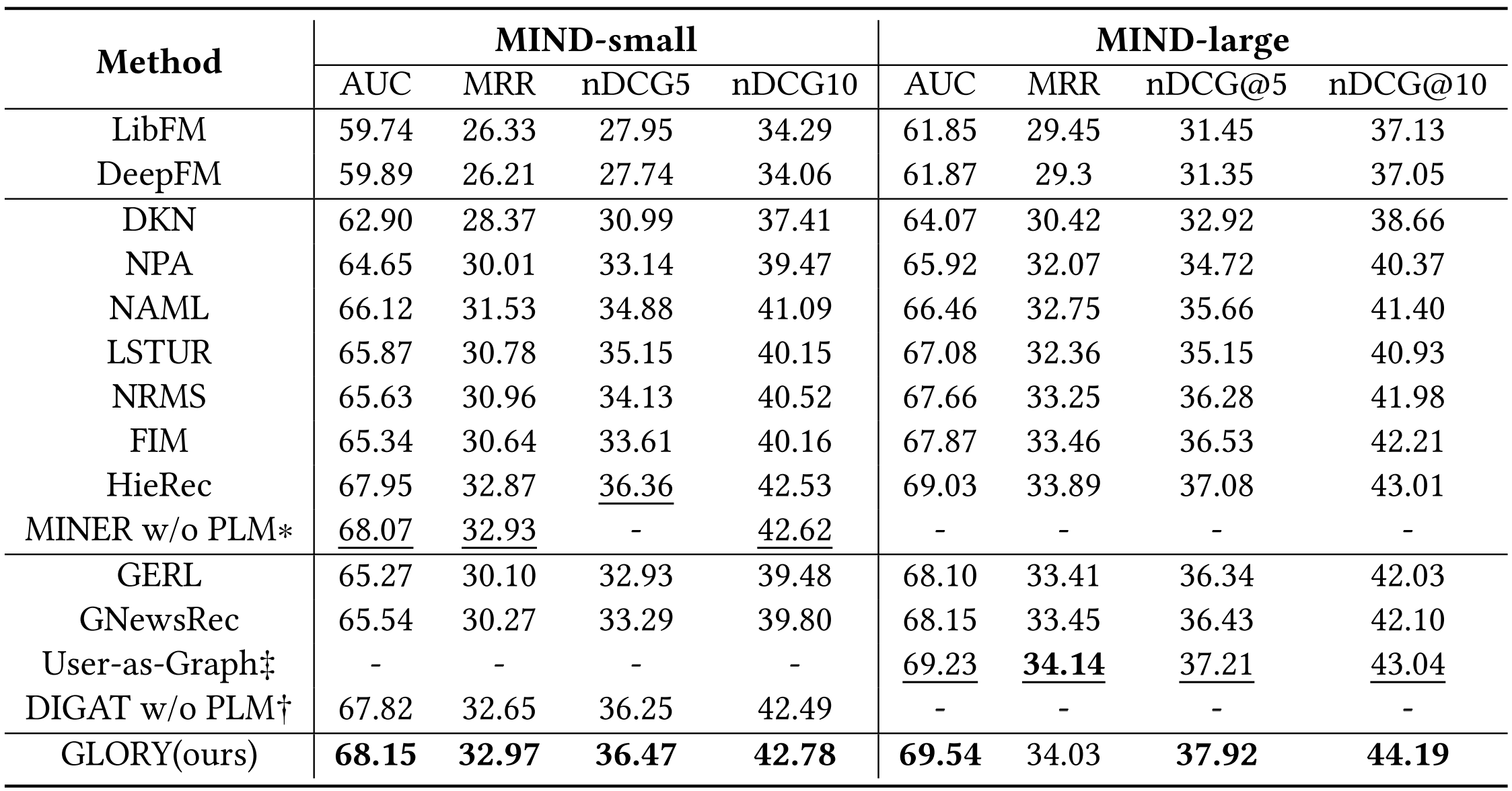
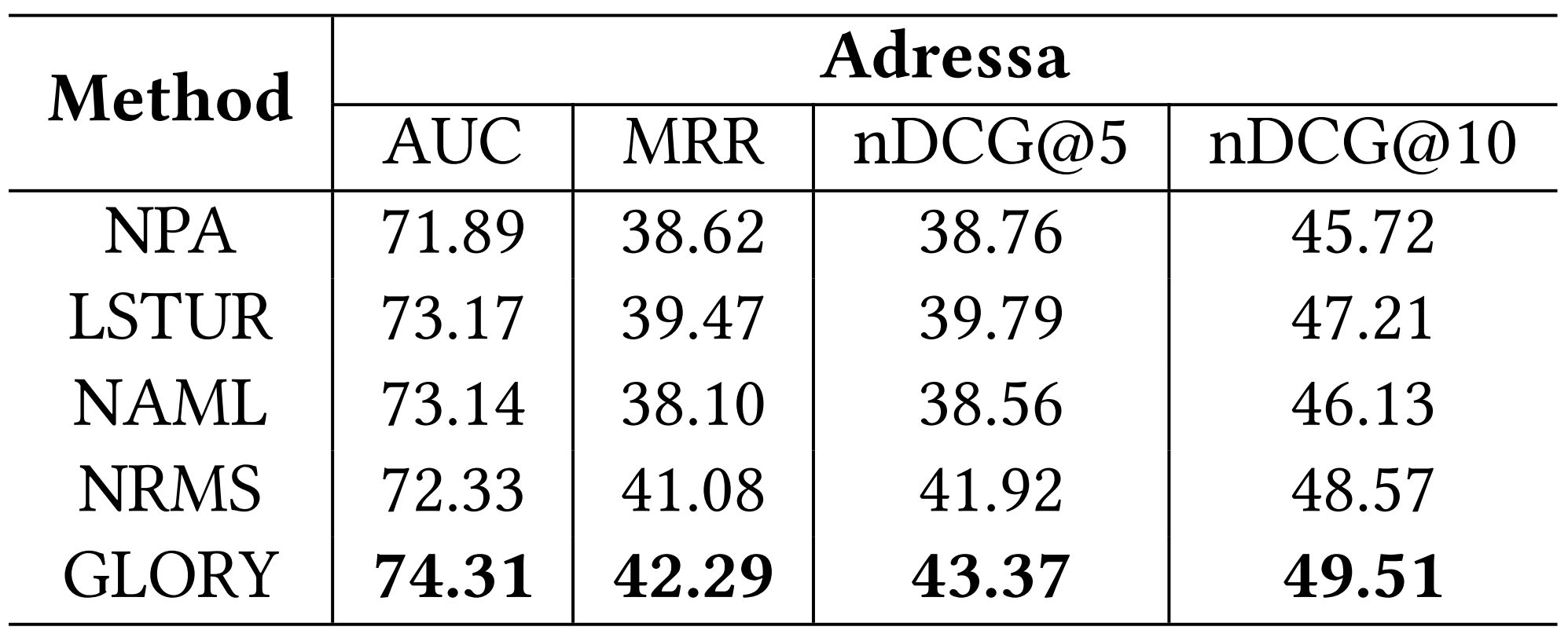
Main Result (Adressa)
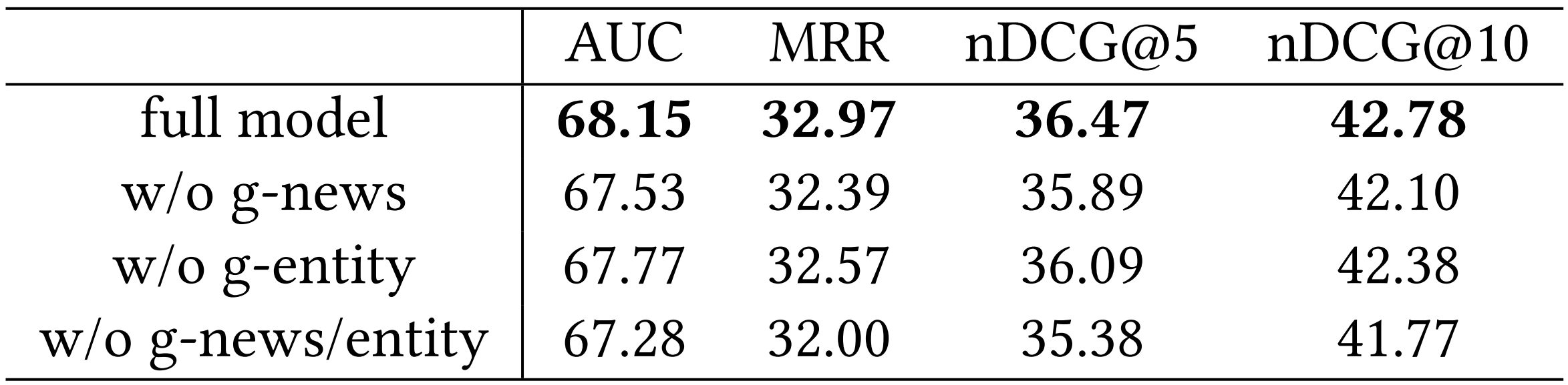
Graph Encoder 모델 별 성능 비교 결과

제안 Global Graph의 사용 여부에 따른 모델 성능 비교
Global News Graph Construction Method에 따른 성능 비교
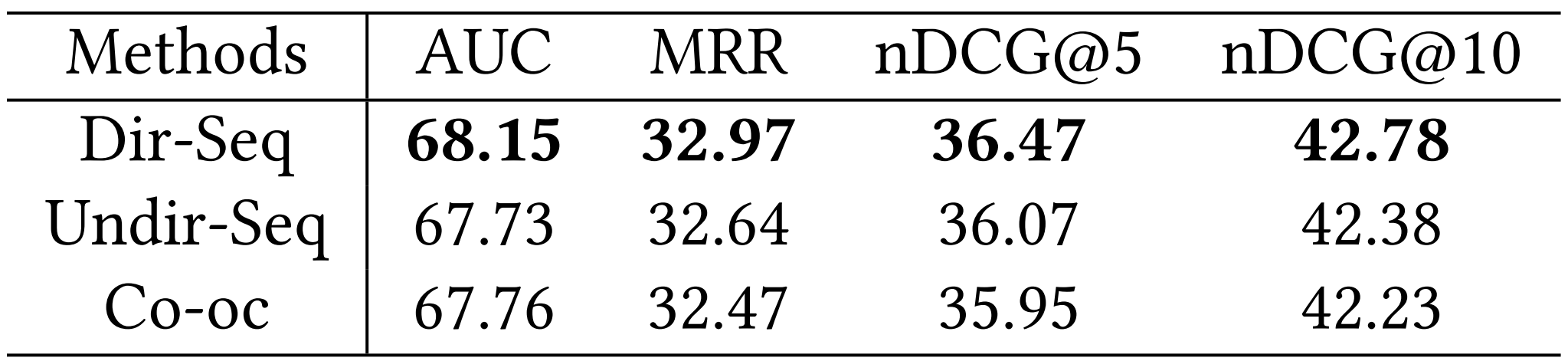
- Dir-Seq: 사용자 읽기 이력 순서에 따라 Directed Edge 생성
- Undir-Seq: 사용자 읽기 이력 순서에 따라 Undirected Edge 생성
- Co-oc: 사용자 읽기 이력 내에 존재하는 뉴스 간에 Complete Graph 생성
Global Entity Graph Construction Method에 따른 성능 비교

- Intra-news: 뉴스 내 등장하는 모든 엔티티 쌍(pair)에 대해 Edge 생성
- i.e., 뉴스 내 등장하는 엔티티 간에는 Complete Graph 생성
- Inter-news: 같은 history에 등장하는 뉴스의 엔티티 간에 Edge 생성
- i.e., 같은 히스토리에 등장하는 뉴스 쌍 간에는 Complete Bipartite Graph 생성
Conclusion
- GLORY는 뉴스 추천 정확도를 향상시키기 위해, 글로벌 그래프 기반 표현 학습을 도입한 새로운 추천 시스템
- 주요 구성 요소
- Global News Graph
- 이는 사용자의 읽기 이력으로 구성된 그래프
- 숨겨진 행동 패턴 및 뉴스 간 관계 학습
- Global Entity Graph
- 뉴스에 등장하는 엔티티 간의 관계 반영
- 후보 뉴스와 히스토리 뉴스 간의 깊은 연관성 포착
- Local + Global Fusion
- 로컬 표현과 글로벌 표현을 aggregator로 통합
- 간결한 사용자 인코더
- Multi-Head Self-Attention 기반으로 사용자 관심 모델링
- Global News Graph
- 두 개 뉴스 추천 데이터셋(MIND, Adressa)에서 실험 결과
- 기존 SOTA 모델 능가
- 모델 구성 요소 각각의 기여도 검증 완료

댓글남기기