
LLM, RAG, KG, RecSys 트렌드 리뷰
LLM, RAG, KG, RecSys 트렌드 리뷰
- LLM: Large Language Model
- RAG: Retrieval-Augmented Generation
- KG: Knowledge Graph
- RecSys: Recommender System
Improving Multimodal Social Media Popularity Prediction via Selective Retrieval Knowledge Augmentation
논문 정보
- 출판년도: 2025
- 저자: Xovee Xu, Yifan Zhang, Fan Zhou, JingKuan Song
- 기관: University of Electronic Science and Technology of China
- Proceedings of the AAAI Conference on Artifical Intelligence (AAAI)
서론
- 온라인 사용자 생성 콘텐츠(UGC, User Generated Contents)의 인기도를 예측하는 것은 소셜 미디어 추천, 광고, 마케팅 등에 중요
- 기존 연구는 UGC 자체의 텍스트, 이미지 등 멀티모달 특성만을 기반으로 예측
- 그러나 실제 UGC의 인기도는 다른 UGC와의 관계성, 사용자 정보, 유행, 알고리즘 등의 외부 요인에 크게 영향을 받음
제안 기법: 지식 검색 기반 멀티모달 인기도 예측 프레임워크
- 멀티모달 + 메타 기반 검색
- 단순히 의미적으로 유사한 콘텐츠를 검색하는 것이 아닌
- 이미지와 텍스트의 의미, 사용자 정보 및 게시물 메타데이터 까지
- 위 피쳐들을 고려하여 다양한 맥락적으로 연관된 UGC들을 검색
- RRCP(Relative Retrieval Contribution to Prediction)
- 검색된 UGC 중, 예측에 정말 기여하는 콘텐츠만 선택하기 위한 measure
- 제안 measure를 통해 잡음이나 무관한 콘텐츠를 제거, 모델의 정확도 개선
- Vision-Language Graph Neural Netowrk
- 최종적으로 선택된 콘텐츠 간의 관계를 그래프 형태로 학습
- 이미지와 텍스트를 함께 처리하는 GNN을 통해 컨텍스트 정보 강화
GraphArena: Evaluating and Exploring Large Language Models on Graph Computation
논문 정보
- 출판년도: 2025
- 저자: JianHeng Tang, Qifan Zhang, Yuhan Li, Nuo Chen, Jia Li
- 기관: Hong Kong University of Science and Technology (Guangzhou)
- The 30th International Conference on Learning Representations (ICLR)
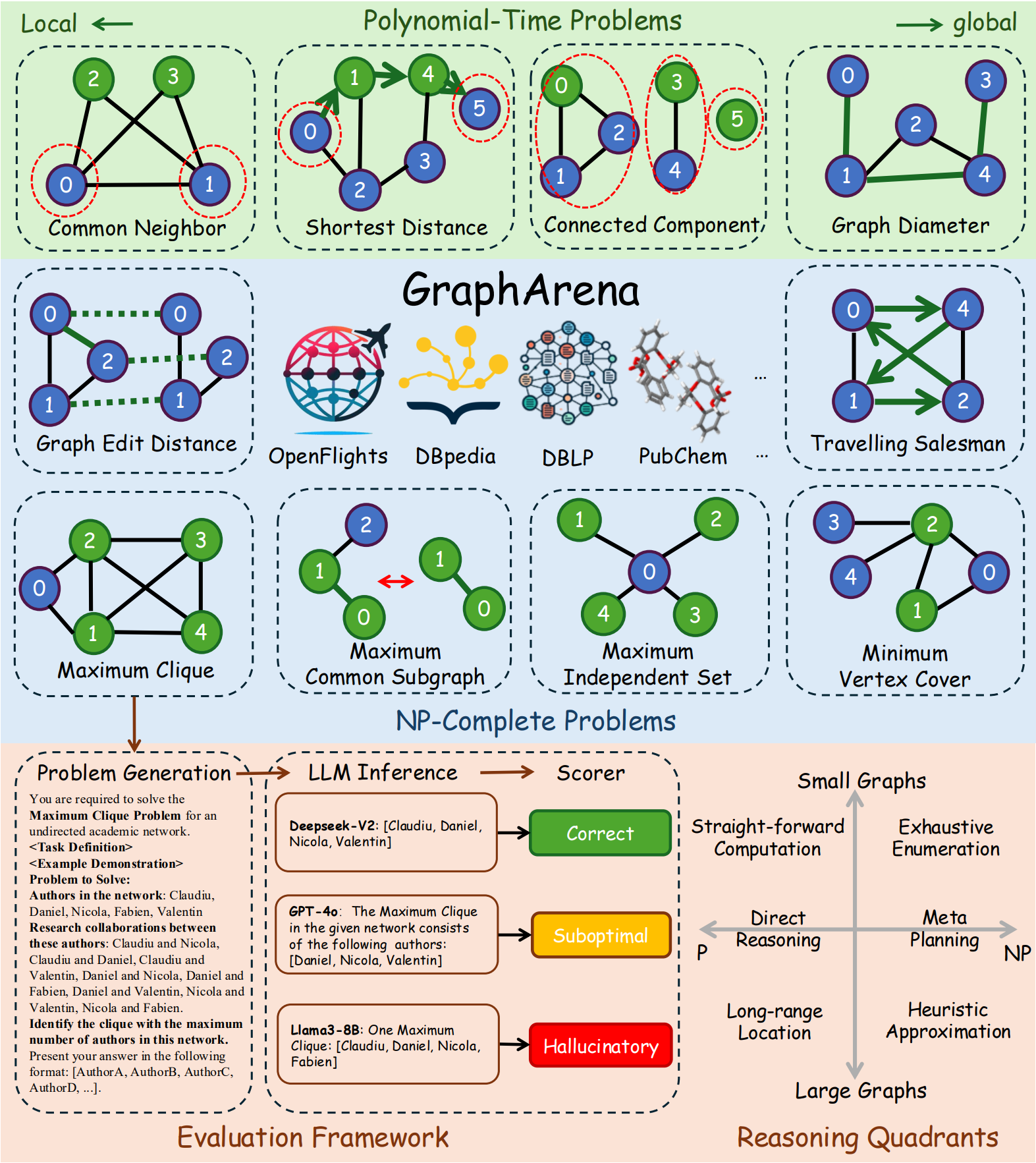
문제 상황
- LLM들의 성능 경쟁이 치열해짐에 따라, 이들을 평가할 수 있는 벤치마크 도구 필요
- 제안 논문은 현실 기반 그래프 계산 문제에서 LLM을 평가
평가 대상 과제
- 총 10개 과제 포함
- 4 Polynomial-time Problems
- Connected Component, Shortest Distance, Diameter, Common Neighbor
- 6 NP-Complete Problems
- Graph Edit Distance, Maximum Clique, Maximum Common Subgraph, Maximum Independent Set, Minimum Vertex Cover, Traveling Samlesman
- 4 Polynomial-time Problems
데이터셋
- DBLP (협업), Social Network, DBpedia (KG), OpenFlights (공항), PubChem (화학 분자), 등의 현실 그래프 데이터 사용
- Random Walk with Restart로 현실성 있는 서브그래프 추출
- 최대 6,000 tokens -> long context 문제도 유도
평가 지표
- LLM의 출력은 아래 4가지 중 하나로 분류
- ✅ Correct: 정확하고 최적해
- e.g., 최대 클리크 문제에서 크기 4짜리 클리크를 정확히 찾음
- ⚠️ Suboptimal: 실행 가능하지만, 근사해
- e.g., 클리크는 맞지만 크기가 3으로 최적보다 작음
- ❌ Hallucinatory: 출력 형식만 맞고, 논리적으로 불가능
- e.g., 클리크로 출력한 노드와 에지 리스트가 실제 주어진 그래프로부터 도출 불가능
- 🚫 Missing: 출력 없음
- LLM이 멈추거나 “I’m not sure…“과 같은 대답
- ✅ Correct: 정확하고 최적해
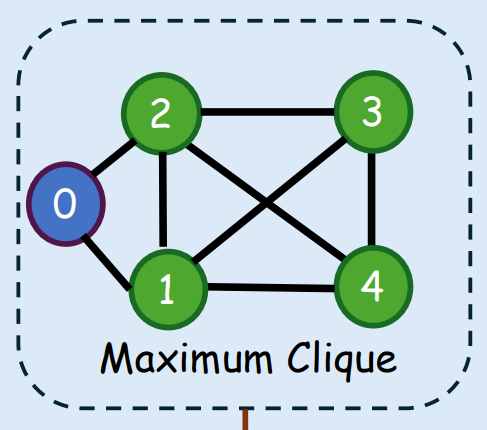
- 참고로, Maximum Clique Problem
- 주어진 그래프에서 부분 그래프를 도출하는데
- 그 부분 그래프는 노드의 개수가 3개 (clique, 삼각형) 이상인 완전 그래프이고
- 주어진 그래프에서 노드의 개수가 가장 많은 완전 부분 그래프를 찾아내면 된다
성능 향상을 위한 시도
- 아래 4가지 접근법 탐색
- Chain-of-thought prompting: 단계적 추론 유도
- Instruction tuning: 그래프 문제 해결 방식에 특화된 fine-tuning
- Code writing: LLM이 직접 코드를 생성해 문제 해결
- Scaling test-time compute: inference 시 더 많은 연산 자원 활용
- 각자 고유한 장단점이 존재
DFA-RAG: Conversational Semantic Router for Large Language Model with Definite Finite Automaton
논문 정보
- 출판년도: 2024
- 저자: Yiyou Sun, Junjie Hu, Wei Cheng, Heifeng Chen
- ICML’24: Proceedings of the 41st International Conference on Machine Learning
문제 상황
- 기존 LLM은 다양한 상황에서 잘 작동하지만, 감정 상담, 고객 응대 등 정해진 응답 규칙이 필요한 경우에 적절한 대응을 하지 못하는 경우가 많음
- 이처럼 정형화된 응답 흐름이 요구되는 상황에서 LLM이 자율적으로 응답을 생성하면 일관성 부족, 규칙 위반이 발생할 수 있음
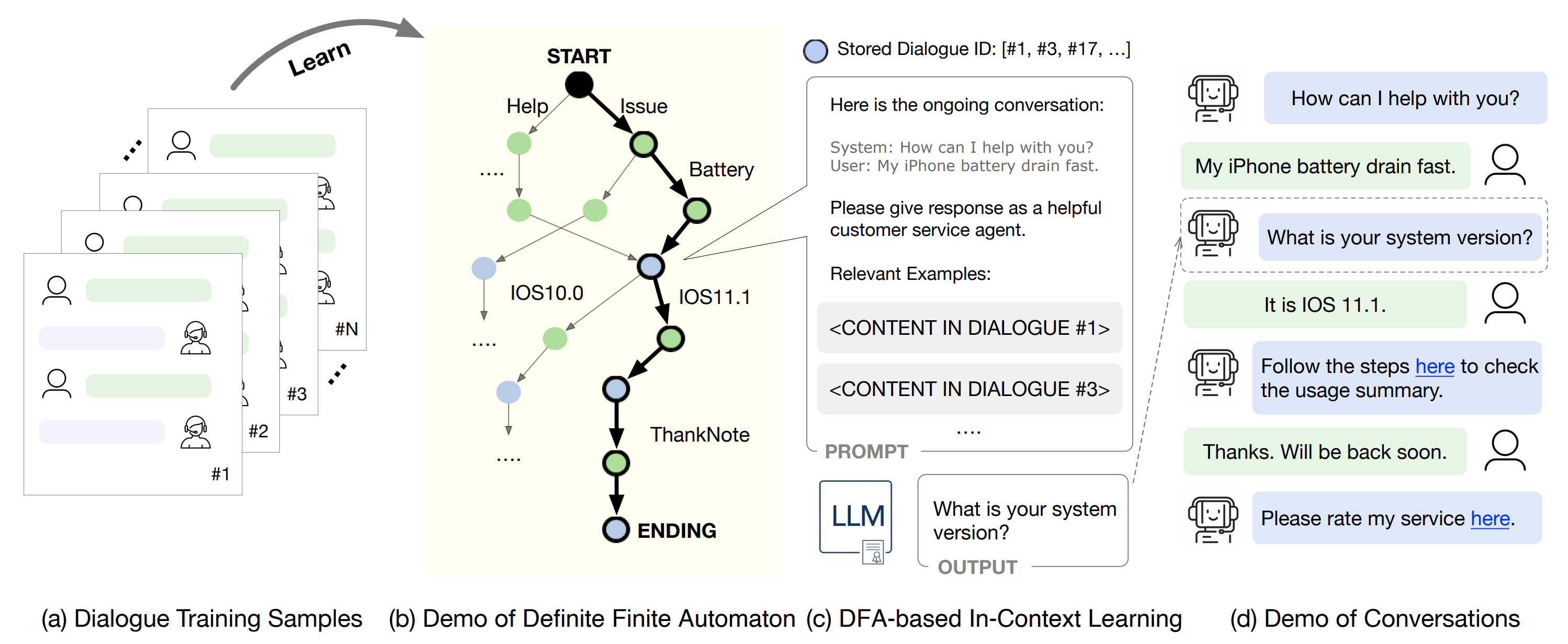
제안 기법: DFA-RAG
- DFA-RAG는 DFA(Deterministic Finite Automaton)와 RAG(Retrieval-Augmented Generation)을 결합한 방식
- DFA의 각 노드를 임베딩하여 RAG 기법을 통해 LLM이 절차에 맞는 응답을 생성하는 방식
MKGL: Mastery of a Three-Word Language
논문 정보
- 출판년도: 2024
- 저자: Lingbing Guo, Zhongpu Bo, Zhuo Chen, Yichi Zhang, Jiaoyan Chen, Yarong Lan, Mengshu Sun, Zhiqiang Zhang, Yangyifei Luo, Qian Li, Qiang Zhang, Wen Zhang, Huajun Chen
- 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
문제 상황
- LLM은 다양한 자연어 처리 작업에서 뛰어난 성능을 보여주나, 환각 현상과 같은 문제점을 여전히 가지고 있음
- 이러한 문제점을 해결하고자 지식 그래프에서 정보를 추출하여 LLM에 투입하는 RAG 기술들이 제안됨
- 그러나, 사실 기반 구조인 지식 그래프 (Knowledge Graph)와 LLM은 아직 충분히 결합되지 않음
- KG는 보통 (주어, 관계, 목적어) 형식의 트리플(triple) 구조를 가지며, 환각이 거의 없는 신뢰할 수 있는 정보 체계임
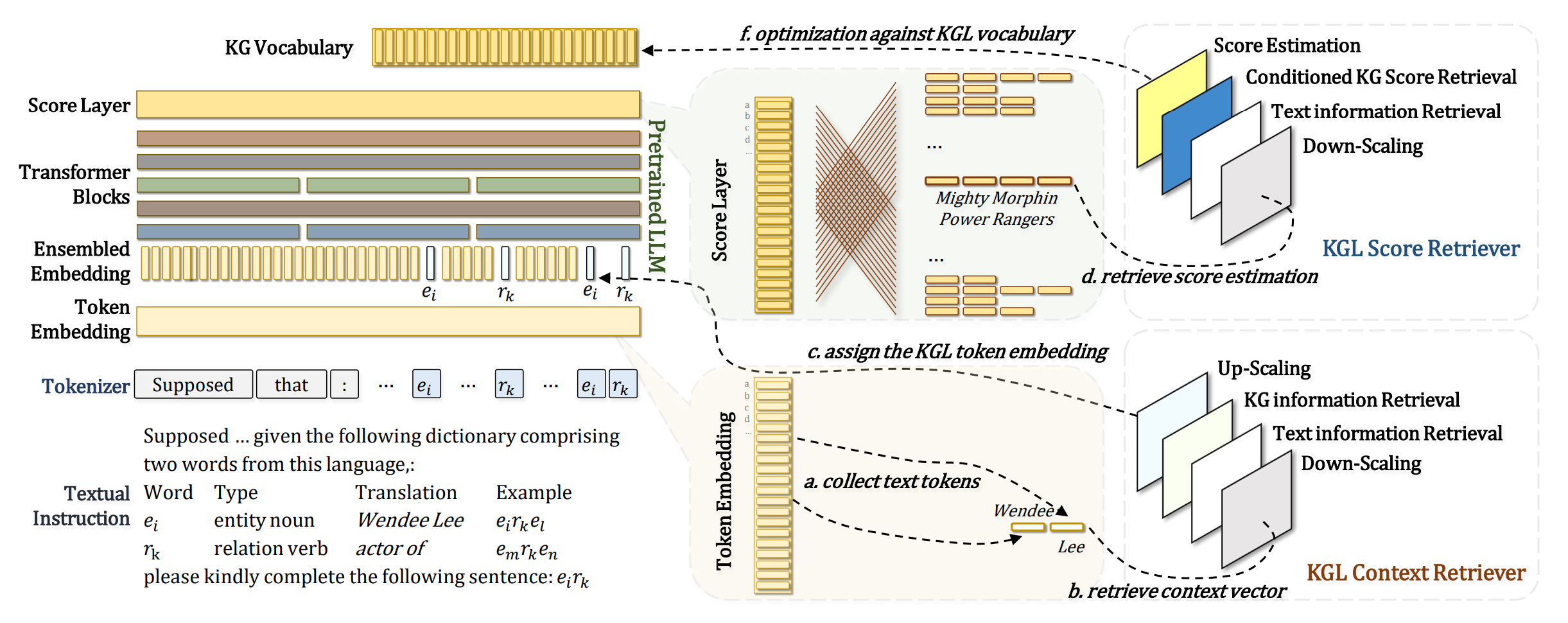
제안 기법: KGL(Knowledge Grpah Language)
- 이에 논문은 LLM이 KG 기반 정보를 좀 더 잘 다룰 수 있도록 KGL(Knowledge Graph Language)이라는 특수 언어를 제안
- KG의 텍스트 자체를 수정하는 Hard한 방식이 아닌, 제안 모델을 통해 KG에서 추출되는 임베딩 토큰 벡터를 LLM이 더 잘 이해할 수 있는 형태로 수정하는 Soft한 방식으로 유추됨
Latent Paraphrasing: Perturbation on Layers Improves Knowledge Injection in Language Models
논문 정보
- 출판년도: 2024
- 저자: Minki Kang, Sung Ju Hwang, Gibbeum Lee, Jaewoong Cho
- 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
문제 상황
- LLM이 전문 분야에 널리 사용되면서, 지속적으로 변화하는 지식을 신속하고 정확하게 반영하는 것이 중요
- 기존에는 패러프레이징(paraphrasing)된 데이터를 이용해 파인튜닝(fine-tuning)하는 방식이 일반적
- 기존 방식으로는 아래 두 문제점이 존재
- 높은 계산 비용: 패러프레이징을 위해 외부 모델(예: 다른 LM, LLM)을 반복 사용
- 제한된 다양성: 생성된 문장 수가 적어 지식 일반화에 한계가 존재
제안 기법: LaPael (Latent Paraphrasing on Early Layers)
- 모델 내부에서 입력에 따라 초기 레이어에 노이즈를 가하는 방식으로 페러프레이징
- 이는 잠재 표현(latent representation) 수준에서 동작. 이에 따라 아래의 장점이 존재
- 입력에 따른 다양하고 일관된 문장 표현 생성 가능
- 외부 모델 없이 내부에서 직접 패러프레이징
- 매번 지식이 업데이트 될 때마다 새로운 문장을 다시 만들 필요가 없음
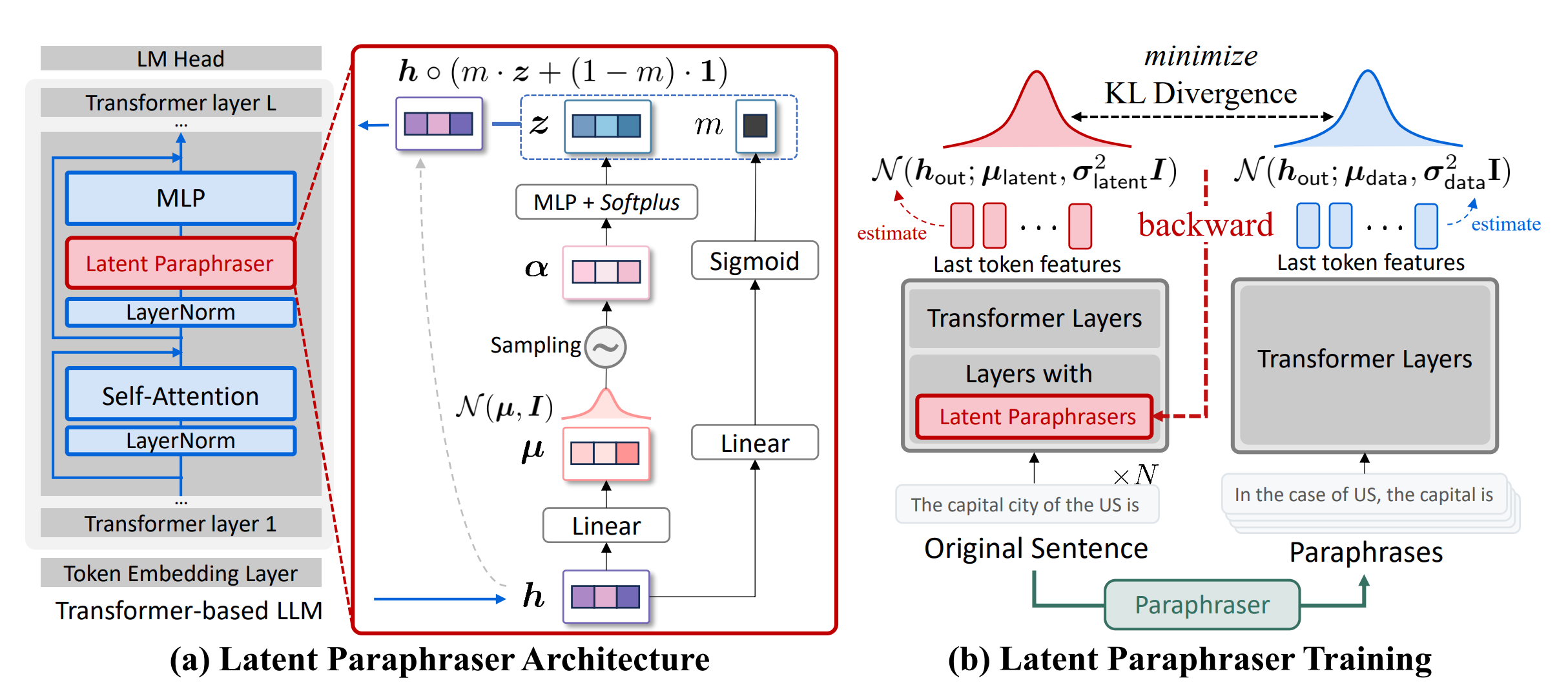
- 기존 Transformer 구조에 Latent Paraphraser 레이어를 추가
- Latent Paraphraser 레이어를 제안하는 KL Divergence Loss Function으로 잘 학습시키면 적은 양의 데이터로 fine-tuning이 가능하다는 것으로 유추됨
- Early Layers?? 논문을 다 읽어보진 않았으나.. 초반 Transformer Layer에만 Latent Paraphraser를 추가하는 방식??
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
논문 정보
- 출판년도: 2024
- 저자: Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, Bryan Catanzaro
- 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
서론
- 대형 언어 모델(LLMs)이 RAG 시스템에서 문맥 순위 결정(context ranking)과 응답 생성(answer generation)을 동시에 수행할 수 있도록 학습시키는 새로운 방식 제안
연구 배경
- RAG(Retrieval-Augmented Generation)
- LLM이 검색기(retriever)를 통해 문맥(top-k 문서)를 가져오고, 그 문맥을 바탕으로 응답 생성을 수행하는 프레임워크
- 기존 RAG는 문맥 랭킹(ranking)과 생성(generation)을 분리된 모델로 처리
- 문맥 랭킹은 별도의 모델(expert ranker)가 수행
- LLM은 응답 생성만 담당
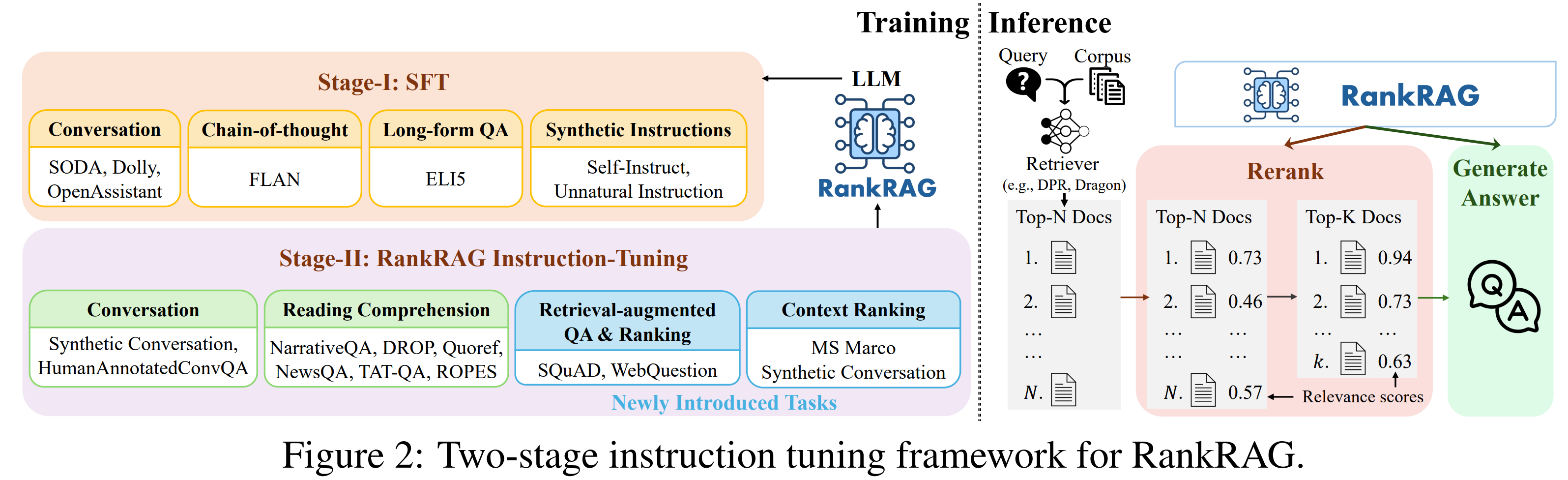
제안 모델: RankRAG
- RankRAG는 하나의 LLM이 문맥 순위 매기기와 응답 생성을 동시에 수행하도록 instruction fine-tuning된 프레임워크
- 랭킹과 생성 기능을 단일 LLM에 통합
- 훈련 시, 일부 랭킹 데이터만 소량 포함하여도
- 기존의 랭킹 전용 모델보다 더 좋은 성능
- 동일 LLM에 랭킹 데이터만 대량 학습시킨 모델보다 우수
- 별도의 랭커 모델 없이 RAG 성능 향상
ChatQA: Surpassing GPT-4 on Conversational QA and RAG
논문 정보
- 출판년도: 2024
- 저자: Zihan Liu, Wei Ping, Rajarshi Roy, Peng Xu, Chankyu Lee, Mohammad Shoeybi, Bryan Catanzaro
- 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
서론
- RankRAG와 동일한 NVIDIA 연구팀에서 개발, RankRAG가 더 우수한 모델
- RankRAG의 주요 비교 모델
- ChatQA: 랭킹 정보 미반영
- RankRAG: 랭킹 정보 반영
- NVIDIA RAG, LLMs 연구팀에서 개발한 RAG 모델 순서는 아래와 같음
- ChatQA, RankRAG -> ChatQA2
ChatQA와 RankRAG 성능 비교
- 성능 비교 상의 주요 응답 차이는 아래 그림과 같음
- ChatQA의 경우, 랭크 정보를 반영하지 않은 채로 연관되지 않은 정보까지 retrieval -> 부정확한 응답 생성 가능
- RankRAG는 연관되지 않은 정보를 retrieval 하여도 랭크 정보를 반영하여 더욱 정교한 응답 생성 가능

- 질의: “who hosted and won the inagural world cup?”
-
참고: 1930년에 월드컵은 우루과이에서 처음 개최되었고 우루과이가 우승하였음
- ChatQA: “Germany” (Wrong!!)
- ChatQA는 질의에 대한 top-k 유사 문서를 랭킹 정보 없이 LLM에 투입
- 이에 따라, top-k 문서에 Uruguay, England, France, Germany, … 등이 섞여서 LLM에 투입
- LLM은 부정확한 답변 생성
- RankRAG: “Uruguay” (Correct!!)
- top-k 유사 문서에 대한 랭킹 정보를 반영하여 LLM에 투입
- 랭킹 정보를 반영하여 Uruguay라는 옳바른 답변 생성
ChatQA2: Bridging the Gap to Propriety LLMs in Long Context and RAG Capabilities
논문 정보
- 출판년도: 2025
- 저자: Peng Xu, Wei Ping, Xianchao Wu, Chejian Xu, Zihan Liu, Mohammad Shoeybi, Bryan Catanzaro
- 13th International Conference on Learning Representations (ICLR 2025)
문제 상황
- 상용 모델(GPT-4-Turbo 등)은 128K 이상의 초장문(long context) 처리와 고성능 RAG에서 우수
- 그러나, 오픈소스 모델들은 아직 그 수준에 도달하지 못함
제안 모델: ChatQA 2
- 기반: Llama 3.0 (70B)
- 컨텍스트 윈도우: 8K -> 128K 확장
- 목적: long context 처리 능력, RAG 능력 강화
훈련 방식
- 컨텍스트 확장 학습
- 기존 8K에서 128K까지 입력 길이 학습
- 초장문(long context)에서도 성능 저하 없이 작동하도록 설계
- 3단계 Instruction Tuning
- 1단계: 일반적인 명령어 이해 및 수행 능력 강화
- 2단계: RAG 태스크에 특화된 학습
- 3단계: 초장문(long context) 이해 능력 강화
The Elephant in the Room: Rethinking the Usage of Pre-trained Language Model in Sequential Recommendation
논문 정보
- 출판년도: 2024
- 저자: Zekai Qu, Ruobing Xie, Chaojun Xiao, Xingwu Sun, Zhanhui Kang
- RecSys’24: Proceedings of the 18th ACM Conference on Recommender Systems
문제 상황
- Elephant in the Room
-
Pre-trained Language Model in Sequential Recommendation
- 시퀀스 추천 시스템에 언어 모델 집어넣기 = 내 방에 코끼리 집어넣기
- PLM(Pre-trained Language Model)을 시퀀스 추천 시스템에 사용하는 것은 비효율적
- 소폭의 성능 향상, 연산량 대폭 증가

구체적 문제 상황
- 기존 PLM 기반 SR(Sequence Recommendation) 모델은 PLM의 파라미터를 거의 그대로 사용하면서
- 행동 시퀀스에 잘 맞도록 최적화도 부족
-
모델 크기에 비해 성능 효율이 떨어짐
- 즉, PLM이 가진 능력을 제대로 활용하지 못하면서 비효율적인 계산 자원만 낭비하는 경우가 다수
제안 개선 방안
- PLM으로는 아이템 임베딩만 초기화
- 나머지는 기존 ID 기반 SR 모델을 그대로 사용하는 방식
-
이를 통해 추론 시점에는 PLM이 개입하지 않아 추가적인 연산 비용이 없음
- Abstract만 읽고 개인적으로 생긴 의문점
- Inference 연산 시에 PLM은 작동시키지 않고 메모리나 디스크에 저장된 임베딩 벡터만 불러와서 사용한다는 것인데..
- PLM 임베딩 벡터 자체는 저장된 것을 사용한다 하여도, 추천 시스템 자체에서도 linear transformation이나 추가적인 attention 연산을 수행하는 것이 일반적인 상황일 것
- PLM에서 추출한 임베딩 자체도 이미 비대한 고차원 벡터인데, 이를 활용하는 것은 여전히 고비용 연산이지 않은가..?
- 즉, 몇 천 차원 벡터를 추천시스템에 사용하겠다는 것은 여전히 합리적이지 않아 보이는 선택
Knowledge-based Multiple Adaptive Spaces for Recommendation
논문 정보
- 출판년도: 2023
- 저자: Meng Yuan, Fuzhen Zhuang, Zhao Zhang, Deqing Wang, Jin Dong
- RecSys’23: Proceedings of the 17th ACM Conference on Recommender Systems
문제 상황
- KG는 풍부한 의미적 정보를 제공하기 때문에 추천 시스템에서 활발히 사용되고 있음
- 기존 대부분의 KG 기반 추천 모델은 유클리드 공간(Euclidean Space)만을 전제로 설계
- 그러나 실제 그래프 데이터는 비유클리드 특성(Hyperbolic, Spherical 등)을 많이 가지고 있어 이러한 단일 공간 모델은 한계가 존재
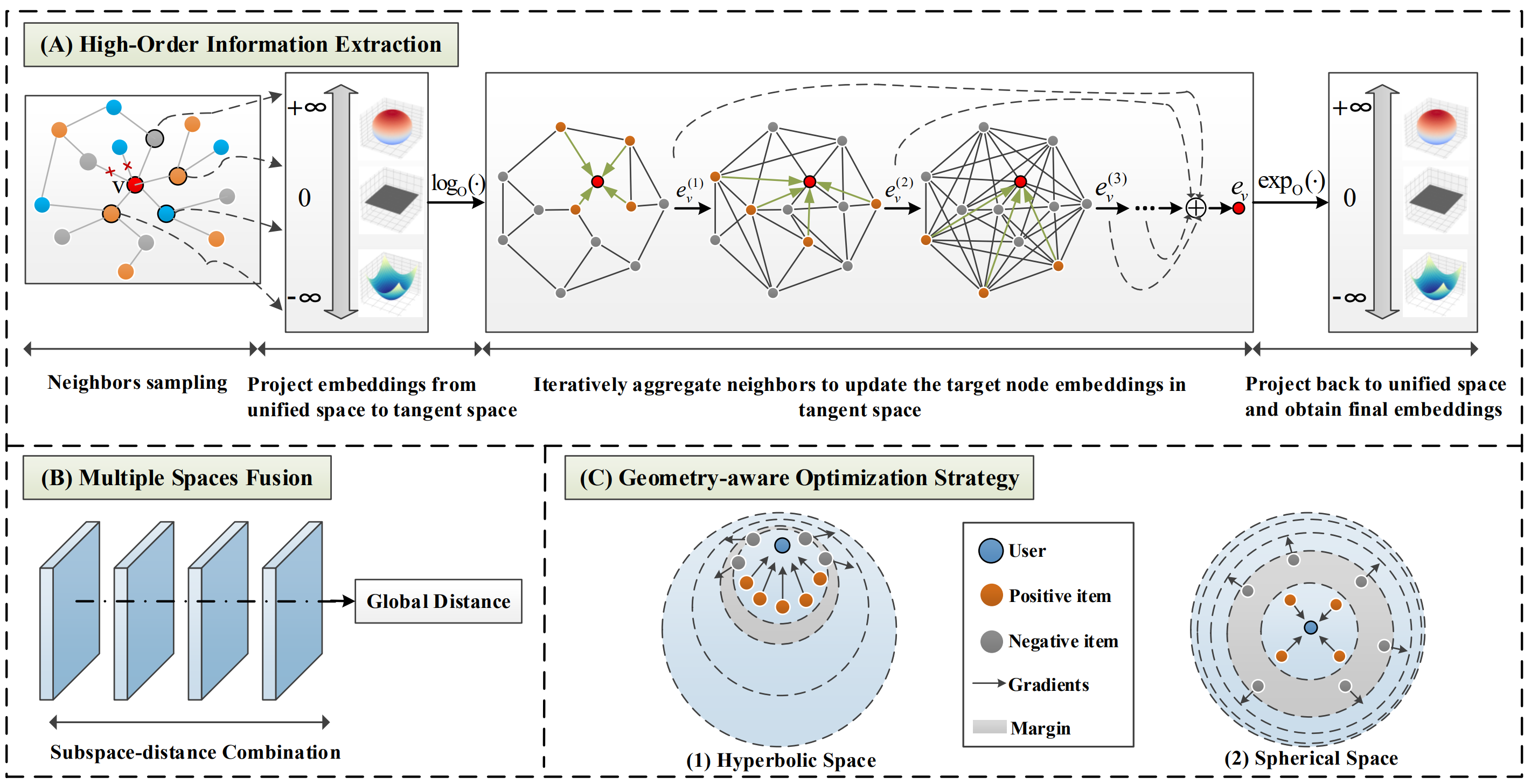
제안 기법: MCKG
-
지식 그래프(KG)를 활용한 추천 시스템에서, 비유클리드 공간 구조를 고려하여 더 정교하고 효과적인 표현 학습을 수행하는 방법인 MCKG를 제안
- MCKG: Multi-Curvature Knowledge Graph
- 통합 임베딩 공간(Unified Embedding Space)
- 유클리드(Euclidean), 쌍곡(Hyperbolic), 구면(Spherical) 공간 모두를 고려할 수 있는 하이브리드 공간 설계
- 멀티 공간 융합 (Multi-space Fusion)
- 각 공간에서 학습된 표현을 어텐션(attention) 기반으로 융합하여 정보 전파 품질 향상
- 기하 기반 최적화(Geometry-aware Optimization) -> convex optimization??
- 하이퍼볼릭 및 스페리컬 공간의 기하 구조를 고려해 margin 크기를 위치에 따라 조절
- 중심에 가까운 영역: 작은 margin -> 유사한 아이템 구별 용이
- 외곽 영역: 큰 margin -> 오차 허용성 향상
- 이 방식은 Unified Space에서 정확도와 안정성 모두를 확보하는 데에 기여
- 하이퍼볼릭 및 스페리컬 공간의 기하 구조를 고려해 margin 크기를 위치에 따라 조절
Heterogeneous Knowledge Fusion: A Novel Approach for Personalized Recommendation via LLM
논문 정보
- 출판년도: 2023
- 저자: Bin Yin, Junjie Xie, Yu Qin, Zixiang Ding, Zhichao Feng, Xiang Li, Wei Lin
- RecSys’23: Proceedings of the 17th ACM Conference on Recommender Systems
문제 상황
- 사용자 행동은 단일한 형태가 아니라 heterogeneous하고 diverse함
- 예: 상품 클릭, 장바구니 담기, 구매, 리뷰 작성, 소셜 활동 등
- 기존 추천 시스템은 이 다양한 행동 데이터를 그대로 모델에 입력 그로 인해 아래와 같은 문제가 발생
- 특징 희소성(feature sparsity)
- 지식 단편화(knowledge fragmentation)
- 이는 결국 추천 품질 저하로 이어짐
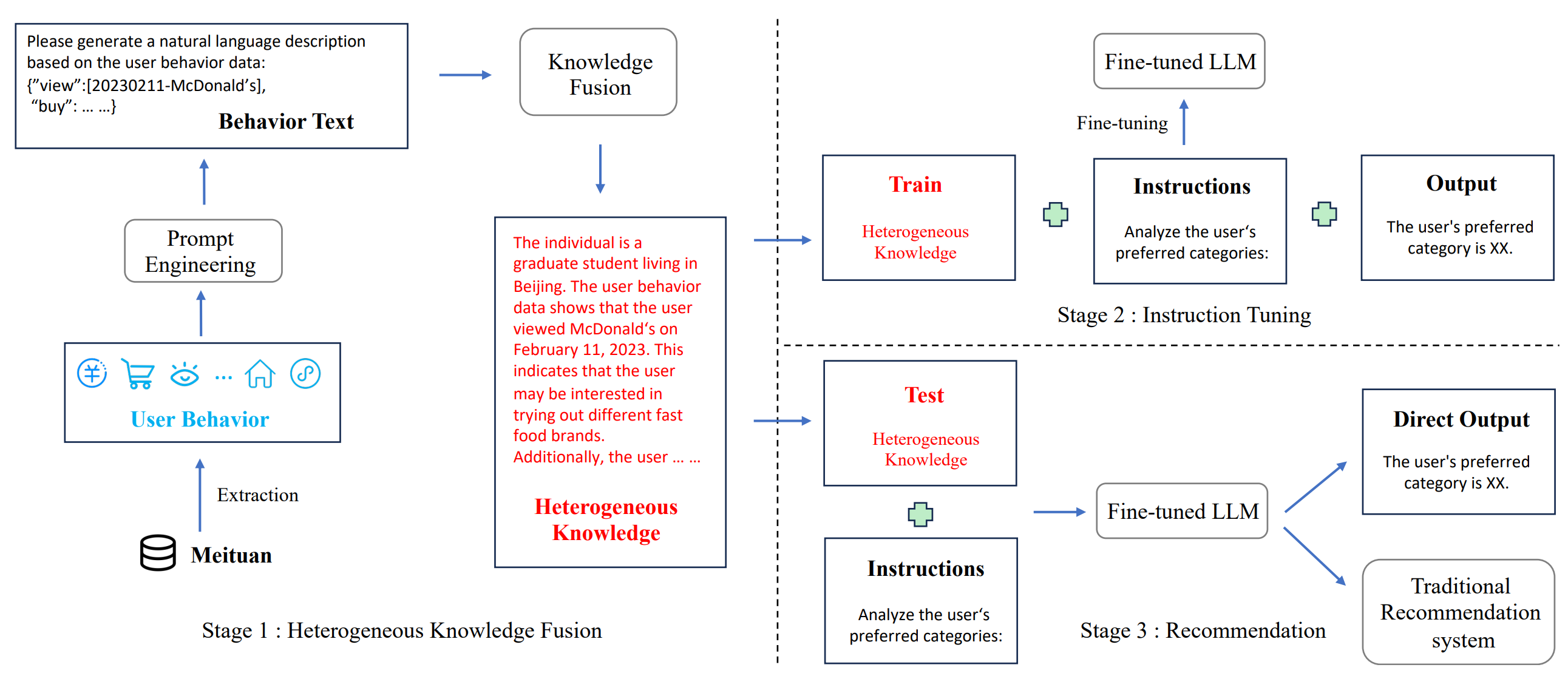
제안 기법: Heterogeneous Knowledge Fusion
- 제안 방법
- Heterogeneous한 사용자 행동 데이터를 LLM을 통해 변환 및 통합(fusion)
- 이를 기반으로 개인화 추천 수행
- 구성 요소
- Heterogeneous 행위 패턴에서 지식 추출
- 각 행동 유형을 언어화, LLM이 이해 가능한 형태로 표현
- 행위 패턴 마이닝 + 토크나이징 및 벡터화
- LLM 기반 지식 융합 (Heterogeneous Knowledge Fusion)
- 추출된 다양한 행동 데이터를 하나의 사용자 문맥(context)로 결합
- Instruction Tuning
- 위에서 생성한 행동 기반 사용자 문맥 + 추천 태스크 결합
- LLM에게 “이 사용자가 어떤 아이템을 좋아할까?”f는 지시 형태로 fine-tuning
- 즉, LLM을 개인화 추천 특화 모델로 미세조정
- Heterogeneous 행위 패턴에서 지식 추출
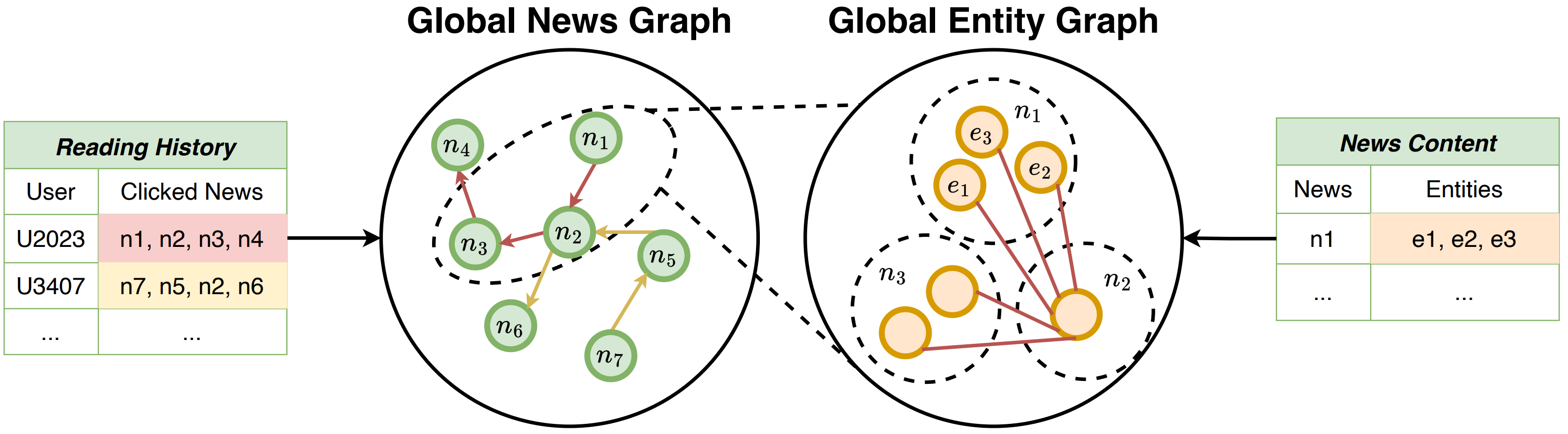
✨Going Beyond Local: Global Graph-Enhanced Personalized News Recommendations
논문 정보
- 출판년도: 2023
- 저자: Boming Yang, Dairui Liu, Toyotaro Suzumura, Ruihai Dong, Irene Li
- RecSys’23: Proceedings of the 17th ACM Conference on Recommender Systems
문제 상황 (기존 개인화 뉴스 추천 시스템의 한계)
- 개인 사용자의 뉴스 클릭 이력만을 활용
- 주로 텍스트 기반의 의미 추출(NLP)에 집중
- 사용자의 숨은 동기나 전반적인 뉴스 트렌드를 반영하지 못함
- 결과적으로, 추천 다양성 부족 및 예측 정확도가 저하
제안 모델: GLORY(Global-LOcal news Recommendation sYstem)
- 로컬 정보(local history)와 글로벌 정보(global graph-based behaviors)를 결합
- 사용자와 뉴스 콘텐츠에 대한 풍부하고 다양성 높은 표현 학습
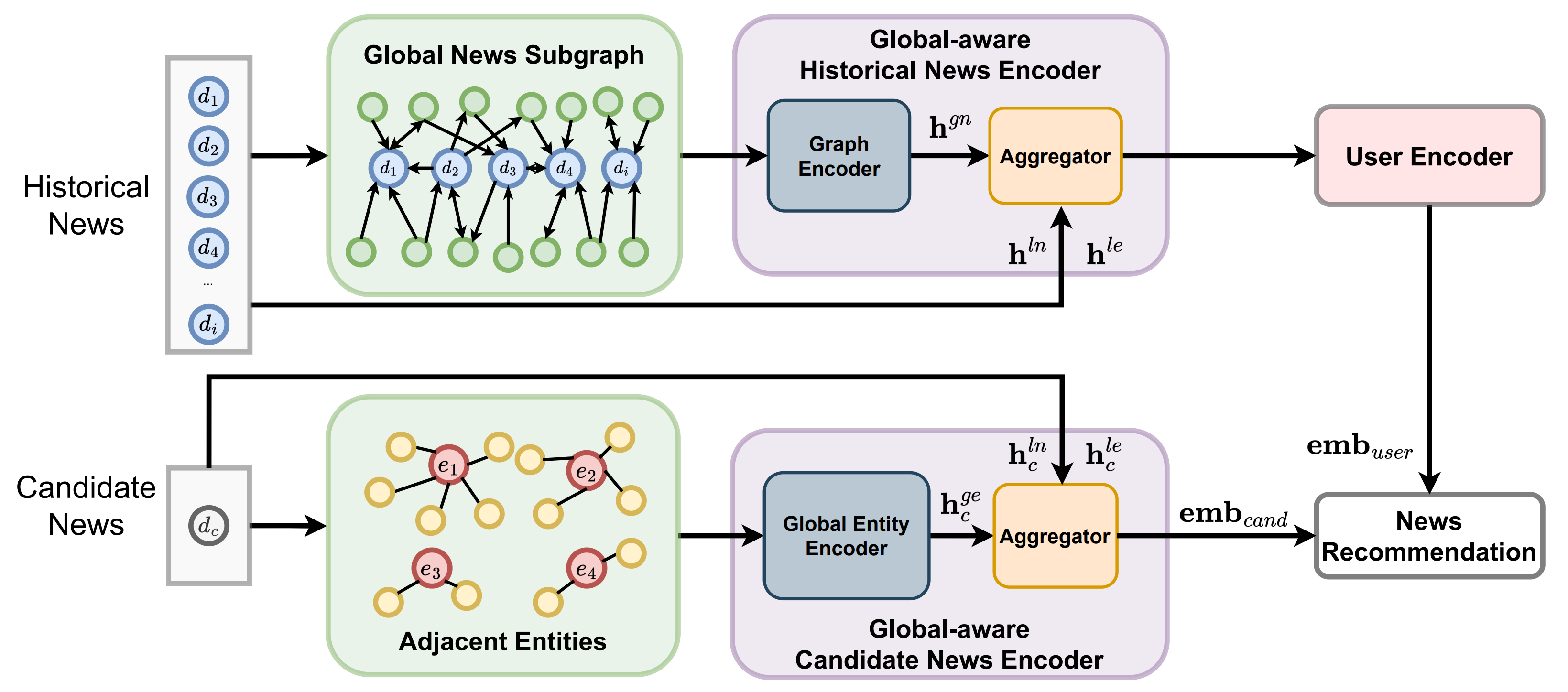
- 모델 구성
- Global-aware Historical News Encoder
- 전 세계 사용자들이 읽은 뉴스로부터 구축된 글로벌 뉴스 그래프 활용
- Gated Graph Neural Network (GGNN)으로 뉴스 간 관계 학습
- 사용자의 클릭 이력(local history)를 이 그래프에 매핑하여 더 풍부한 히스토리 표현 생성
- Global Candidate News Encoder
- 추천 후보 뉴스에 대해서도 글로벌 엔티티 그래프를 기반으로 표현 강화
- 글로벌 문맥을 반영하여 후보 뉴스 임베딩 생성
- Aggregator 모듈
- 위에서 얻은 히스토리 정보 + 후보 뉴스 정보를 통합하여 최종 추천 수행
- Global-aware Historical News Encoder

댓글남기기