
GRACEFUL: A Learned Cost Estimator For UDFs
GRACEFUL: A Learned Cost Estimator For UDFs
About Paper
- Johannes Wehrstein, Tiemo Bang, Roman Heinrich, Carsten Binnig
- ICDE 2025: IEEE 41st International Conference on Data Engineering
- Technical University of Darmstadt / Microsoft - Gray Systems Lab / DFKI
1. Introduction
1.1. Abstract
1.1.1. User-Defined-Functions (UDFs) are a pivotal feature in modern DBMS…
UDF는 중요하지만 최적화가 어렵다
- SQL만으로는 표현하기 어려운 사용자/비즈니스 로직을 함수로 생성 가능
- 문자열 포맷팅
- 사용자 정의 필터링 조건
- 특정 도메인 전용 계산
- 커스텀 aggregation
- 변환 함수
- 위 예시들은 실제 서비스 환경에서 자주 등장
- 그러나, UDF는 DBMS optimizer 관점에서 다루기 어려운 주제
- UDF 실행에 필요한 cost estimation이 어렵기 때문
1.1.2. 기존 cost model의 한계
- 기존 cost model은 보통 아래 연산들에 대해서는 꽤 잘 작동
- scan, filter, join, sort, aggregation
- 이러한 연산들은 DBMS가 오래 전부터 잘 연구해 온 연산
-
cardinality나 selectivity와 같은 통계 정보를 활용하여 대략적인 비용 추산이 가능
- 그러나, UDF는 내부 구조가 너무 다양해서 이런 전통적 hand-crafted cost function으로 다루기 어려움
- 따라서, 기존 optimizer는
- UDF를 일반 predicate처럼 취급하거나
- UDF 비용을 일정하다고 가정하거나
- 아예 제대로 반영하지 못함
- 그 결과 suboptimal plan, 즉 비효율적인 실행 계획을 선택
1.1.3. GRACEFUL의 제안
- 따라서, GRACEFUL은 learned cost model을 제안
-
사람이 손으로 UDF 비용 공식을 구하는 대신, 데이터와 실행 결과를 바탕으로 모델이 비용을 학습
- GRACEFUL은 query plan과 UDF의 구조를 함께 보고
- 이 UDF가 어떤 구조인지
- 어떤 branch가 얼마나 자주 실행될지
- 어떤 loop가 얼마나 돌 가능성이 있는지
- 데이터 분포가 어떤지
-
를 반영하여 실행 비용을 예측
- 위 예측을 바탕으로 optimizer가 더 좋은 결정을 할 수 있음
1.1.4 대표적인 효과: filter pull-up / push-down
- 일반적으로 DBMS에서는 filter push-down이 좋은 최적화
- 가능한 빨리 filter를 적용하여서 row 수를 줄이면 이후 연산이 빨라짐
- UDF filter는 다를 수 있음
- 어떤 UDF가 매우 비싼 함수라면
- 초반에 많은 row에 대해 해당 UDF를 사용하는 것은 오히려 손해일 수 있음
- 즉,
- 일반 predicate는 빨리 적용하는 것이 좋지만
- 비싼 UDF predicate는 나중에 적용하는 것이 더 좋을 수도 있음
- GRACEFUL은 이런 경우를 비용 예측으로 판단하여
- pull-up (UDF filter 먼저 적용) / push-down (UDF filter를 나중에 적용) 중 결정
- 그 결과, 약 50배의 속도 개선을 달성
1.1.5 데이터셋 공개
- UDF 쿼리 최적화는 데이터셋이 부족한 분야
-
해당 논문에서 9만 개 이상의 synthetic UDF query benchmark를 공개
- 즉, 후속 연구가 쉽게 재현되고 비교 가능한 기반을 제공
1.2. Introduction
1.2.1. “Modern Databases Increasingly Face UDFs”
- 데이터 규모가 계속 증가
- 처리 요구도 점점 복잡해짐
- 따라서, 계산을 DB 바깥으로 빼기 보다는 데이터 가까이서 처리하는 것이 중요
-
이를 위해 DB 내부에서 custom logic을 실행할 수 있는 UDF가 중요해짐
- 즉, UDF는 단순한 부가 기능이 아니라
-
현대 DBMS에서 실제로 많이 사용되는 실전 기능
- 또한, 저자들은 UDF가 데이터센터에서 매일 수십억 번 실행된다는 것을 언급
- 따라서, UDF 최적화가 실제 시스템 성능에 매운 큰 영향을 미칠 수 있음
1.2.2. UDF Optimizations are Crucial
- DBMS의 핵심은 단순히 SQL을 실행시키는 것이 아닌, 효율적인 실행 계획을 고르는 것
- 그러나, UDF는 이 과정에서 문제를 일으킴
- SQL optimizer는 보통 아래를 기준으로 판단
- 어느 join order가 좋은가
- filter를 언제 적용할 것인가
- 어떤 연산을 먼저할 것인가
- 어떤 index를 사용할 것인가
- 이 모든 것은 cost estimation을 바탕으로 작동
- 그러나, UDF가 개입하면 cost estimation이 불명확해져서 optimizer가 잘못된 선택을 할 수 있음
- 특히, UDF에서는 predicate push-down이 항상 좋은 것이 아님
1.2.3. Limited UDF Support in DBMS Cost Estimators
- 사실 UDF를 고려한 query optimization은 오래된 문제
- 과거에도 complex predicate 최적화 문제가 논의됨
-
하지만 보지 못한 UDF의 비용을 일반화해서 예측하는 문제는 아직 해결되지 않았음
- 즉, 기존 연구가 UDF를 빠르게 실행하는 방법이나 특정 상황 최적화는 수행하였더라도
- optimizer가 새로운 UDF를 처음 봤을 때에도 비용을 잘 예측할 수 잇는지에 대한 해법이 부족
1.2.4. The impact of pull-up optimization an a SQL query with a UDF
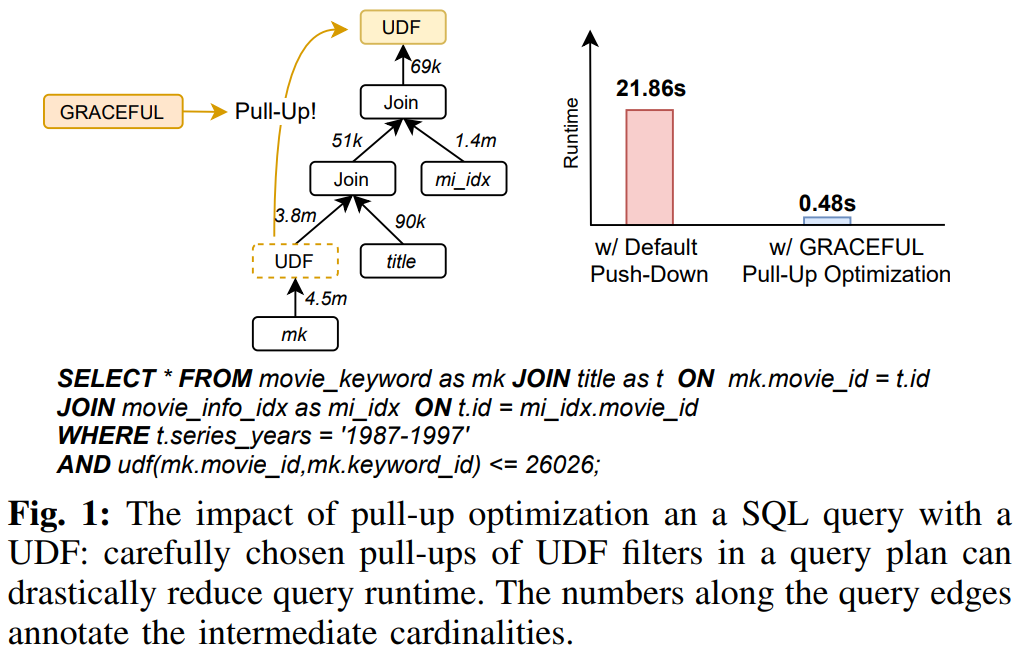
- Given Query
SELECT * FROM movie_keyword as mk JOIN title as t ON mk.movie_id = t.id JOIN movie_info_idx as mi_idx ON t.id = mi_idx.movie_id WHERE t.series_years = '1987-1997' AND udf(mk.movie_id, mk.keyword_id) <= 26026;- 아래 3개 테이블을 EQUI JOIN
- movie_keyword as mk, title as t, movie_info_idx as mi_idx
- EQUI JOIN 조건
- mk.movie_id = t.id = mi_idx.movie_id
- ‘1987-1997’ 연도 조건으로 필터링
- udf(mk.movie_id, mk.keyword_id) <= 26026 조건으로도 필터링
- 아래 3개 테이블을 EQUI JOIN
- 일반적으로는 filter를 빨리 적용하는 것이 좋음
- 해당 원칙에 따라, UDF filter도 우선으로 수행하면 오히려 상황이 안좋아짐
-
UDF를 너무 일찍 적용하면 4.5 million rows에 대해 UDF를 평가해야함
- 한편, join과 다른 조건들을 먼저 수행한 후에 UDF를 위쪽에서 적용하면
- 69k rows에 대해서만 UDF를 수행
-
즉, UDF가 매우 비싸기 때문에 적은 row에 대해 늦게 평가하는 편이 훨씬 이득
- runtime 비교
- 잘못된 plan: 21.86s
- pull-up된 plan: 0.48s
- 위 예시는 아래를 시사
- UDF가 있으면 고전적인 optimizer heuristic이 깨질 수 있음
- 따라서 UDF 비용을 아는 것이 매우 중요
- 정확한 cost estimator만 있으면 엄청난 성능 개선이 가능
1.2.5. Our Proposal: Learned Cost Estimator for UDFs
- 논문은 최근 ML 기반 cost estimation이 좋은 성과를 내고 있음을 언급
-
전통적인 hand-crafted optimizer 대신 학습 기반 방법이 database 분야에서 점점 주목을 받음
- 하지만 기존 learned cost model도 주로 일반 SQL 연산 중심
- UDF 내부 구조까지는 잘 다루지 못함
- UDF 그 자체가 하나의 프로그램이기 때문
- 예를 들어 UDF 내에는
- loop
- if/else
- arithmetic
- string operator
- library call
-
과 같은 구조가 존재
- 따라서, 단순히 query plan만 볼 것이 아니라
-
UDF 자체를 program structure로 표현해야함
- 그래서 GRACEFUL은 query plan + UDF control flow를 함께 보는 모델을 제안
1.2.6. Runtime prediction is hard works
- 프로그램 비용 예측은 원래 어려운 문제
-
일반화해서 생각하면, 이는 Turing의 Halting Problem과 유사해 본질적으로 어려움
- 그러나, DBMS의 UDF는 아래의 특성이 있어 상대적으로 다룰 만함
- UDF는 보통 구조가 크지 않음
- 몇십~몇백 연산 수준
- control flow가 비교적 단순
- loop/branch 수가 제한적
- DBMS 안에서는 UDF에 들어갈 데이터에 대한 정보가 없음
- 어떤 테이블에 적용되는지
- 데이터 분포가 어떠한지
- branch condition이 얼마나 자주 true인지
- 이를 database statistics로 어느 정도 추론할 수 있음
- UDF는 보통 구조가 크지 않음
- GRACEFUL은 단순히 코드 만을 바탕으로 최적화 하는 것이 아니라 (Compiler Optimization)
- 데이터 특성까지 반영하여 비용을 예측 (GRACEFUL)
1.2.7. The Need to Generalize to Unseen UDFs
- UDF는 종류가 매우 다양
- DL 모델 훈련 시점에 본 UDF만 잘 맞추는 모델로는 쓸모가 없음
- 처음 보는 UDF
- 처음 보는 SQL 패턴
- 처음 보는 데이터셋
-
즉, Unseen UDF에도 일반화가 되어야함
- 논문은 GRACEFUL이 아래 세 가지에 대해 generalize할 수 있다고 주장
- unseen UDFs: 훈련 때 없던 새로운 함수 코드
- unseen SQL workloads: 훈련 때와 다른 질의 패턴
- unseen datasets: 훈련 때 없던 데이터셋
1.2.8. 핵심 기술: CFG + GNN + 데이터 통계
1.2.8.1. UDF를 Control Flow Graph (CFG)로 표현
- UDF를 단순 텍스트 코드로 부지 않고
- 프로그램의 구조를 나타내는 Control Flow Graph (CFG)로 표현

- CFG Representation은 아래를 반영하기에 좋음
- branch 구조
- loop 구조
- execution path
- operation 유형
- 즉, UDF를 작은 프로그램 그래프로 보는 것
1.2.8.2. Query Plan과 UDF를 joint representation으로 결합
- UDF는 query 바깥에 따로 존재하는 것이 아니라
-
query plan 안 특정 위치에서 실행
- 따라서,
- query plan 구조
- UDF 구조
- plan 내 UDF의 위치
- 입력 cardinality
- 를 함께 표현해야함
1.2.8.3. GNN으로 비용 예측
- 그래프 구조 데이터이기 때문에 GNN(Grpah Neural Network)를 사용
- GNN은 query plan graph와 CFG 같은 구조적 정보를 반영하기 적합
- 논문은 이를 통해 UDF와 query plan의 joint embedding을 만들고 runtime을 예측
1.2.9. Pull-up advisor
- GNN을 통한 비용 예측 정확도를 통해
-
실제 optimizer task의 pull-up advisor를 구축
- 이 비용 모델을 활용해
- UDF filter를 아래로 내릴지
- 위로 올릴지
-
를 결정하는 의사결정 모듈을 개발
- 이를 통해 단순 예측 정확도 뿐 아니라
- 실제 optimizer decision에 연결했을 때 end-to-end 성능 이득이 크다는 것을 입증
1.2.10. Adaptive Execution is Not to be Preferred
- adaptive execution으로 실행 중간에 plan을 바꾸면
- adaptive execution은 DBMS에 넣기 복잡
- execution paradign 자체가 달라질 수 있음
- 기존 DBMS architecture와 잘 안 맞을 수 있음
- 즉, 현실 시스템 관점에서는
- 기존 optimizer 구조에 자연스럽게 들어가는 cost model 방식이 더 실용적
1.2.11. Contributions
- GRACEFUL 제안
- UDF가 포함된 query plan의 runtime을 예측할 수 있는
- GNN 기반 cost estimator를 제안
- 새로운 UDF 표현 방식
- UDF 구조와 입력 데이터 분포를 반영하는 transferable representation 제안
- 특히 database statistics를 이용해 UDF branch hit-ratio를 추정하는 방식이 핵심
- 실험적 성능 입증
- 정확도 측면에서 우수
- 실제 pull-up / push-down 최적화에 큰 성능 향상을 줄 수 있음
- 코드와 benchmark 공개
- 9만 개 이상의 query, 20개 데이터베이스에 걸친 benchmark 공개
2. Overview of GRACEFUL
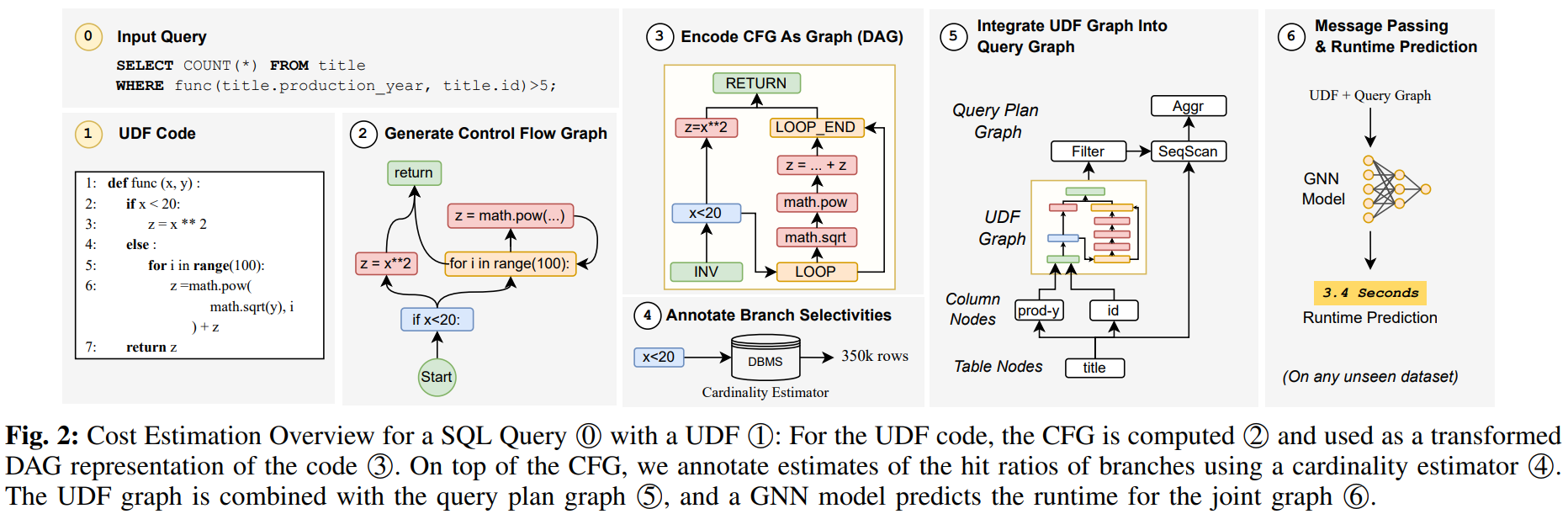
- GRACEFUL의 핵심 구성 4가지
- UDF를 CFG로 표현
- 그 CFG를 cost estimation에 맞춰 변형하고 annotation을 붙임
- 그 UDF 그래프를 query plan 그래프와 합침
- 합쳐진 그래프를 GNN에 넣어 runtime을 예측
- 즉, 단순히 SQL plan만 보는 것도 아니고, UDF 코드만 보는 것도 아님
- Query, UDF, 데이터 통계를 함께 모델링
2.1. Key Ideas of Cost Model
2.1.0. CFG Introduction
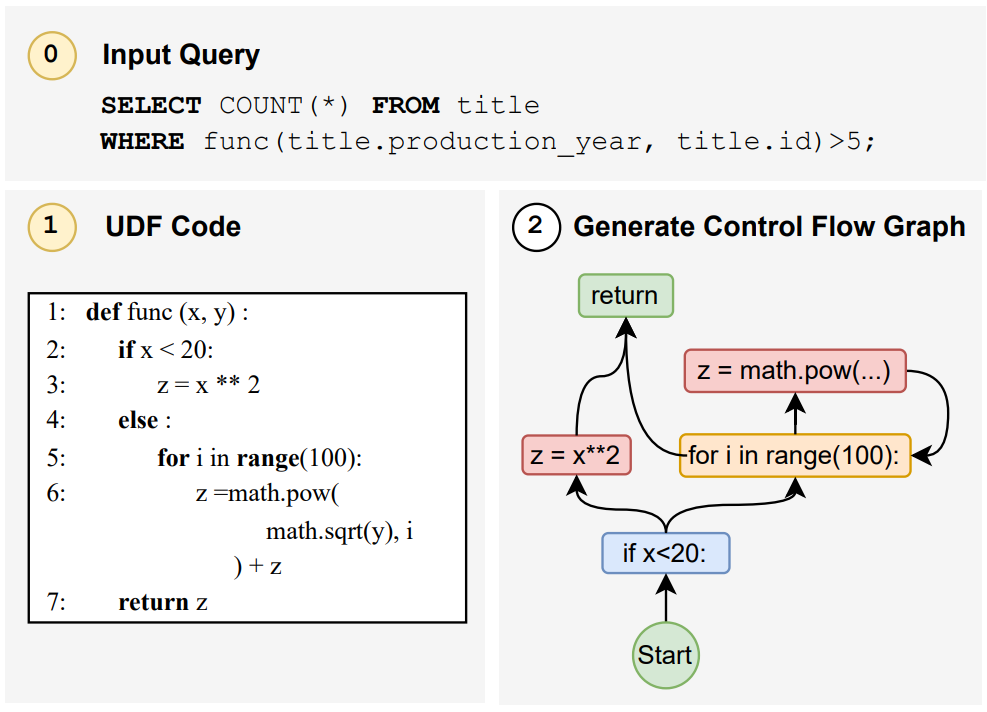
2.1.0.1. 그래프 구조로 추상화
- 기존 DBMS의 cost model은 대체로 아래 정보를 고려
- query plan operator 종류
- cardinality
- join type
- scan row 수
- predicate selectivity
- 그러나, UDF가 개입하면 위 정보만으로는 부족
- UDF 내부에서 발생하는 연산에 따라 runtime에 큰 영향을 주기 때문
- 단순 덧셈
- 문자열 파싱
- 반복문
- 여러 branch를 가짐
-
위 경우에 따라 비용이 완전 달라짐
- 따라서, GRACEFUL은 runtime estimation을 위해 필요한 대상을 모두 그래프로 추상화
- SQL query plan → query graph
- UDF code → control flow graph
- data characteristics / cardinalities → node/edge annotation
- 즉, 단순한 벡터 feature 몇 개가 아니라
- 구조적 정보(structure)를 가진 그래프로 관찰
2.1.0.2. UDF를 CFG로 표현하는 이유
- CFG(Control Flow Graph)는 프로그램의 실행 흐름을 그래프로 나타낸 것
- node: 코드 블록 또는 statement
- edge: 실행 흐름 또는 제어 경로
- e.g.,
def my_func(i, numbers): if i < len(numbers): return numbers[i] % 2 == 0 return None- 위 코드를 CFG로 만들면 아래와 같은 형태가 됨
- 이를 활용해 CFG는 프로그램의 branch, loop, 실행 순서를 자연스럽게 담을 수 있음
2.1.0.3. 왜 UDF를 CFG로 보는가?
- UDF는 결국 작은 프로그램
- 따라서 runtime은 다음에 의해 결정됨
- 어떤 연산이 있는가
- 몇 개의 branch가 있는가
- loop가 있는가
- 어떤 경로가 자주 실행되는가
- 어떤 연산이 반복되는가
- 위와 같은 정보는 단순 SQL operator feature로는 담아내기 어려움
-
CFG로 포현해야 자연스럽게 반영됨
- 즉, UDF는 opque black-box가 아니라, 구조를 가진 code graph로 보자는 제안
2.1.0.4. naive CFG 만으로는 부족하다
- CFG는 코드 블록과 control edge만 표현
- 대용량 데이터를 다루는 DBMS에서는 CFG 만으로 cost estimation이 충분하지 않음
- 어떤 statement가 어떤 데이터에 얼마나 자주 수행되는지가 중요하기 때문
2.1.1. Our UDF Representation
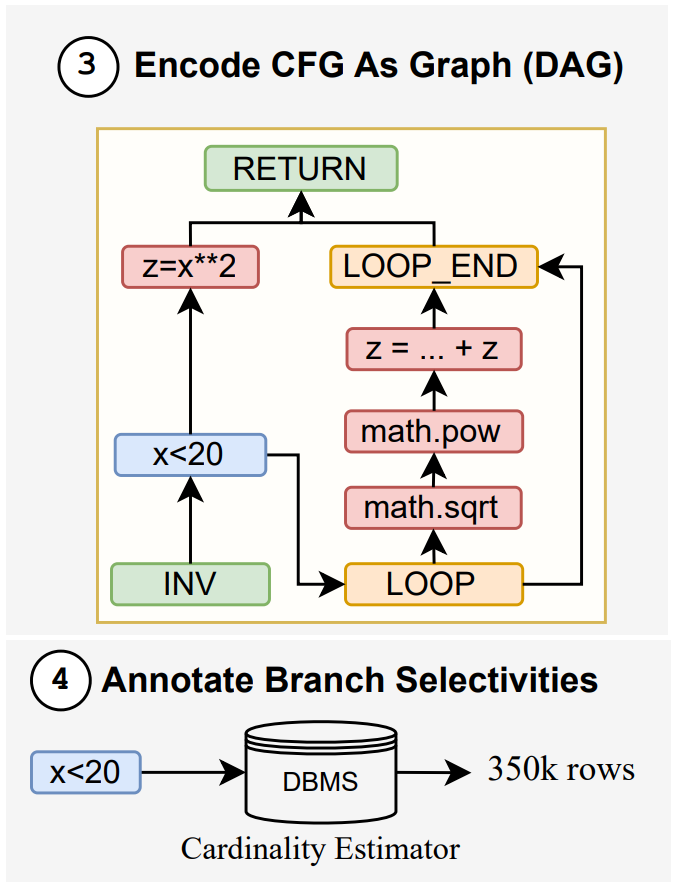
- 제안 논문은 CFG에 추가적인 변형을 수행
- exploit loop end 추가
- single-statement CFG로 변환
2.1.1.1. exploit loop end 추가
- 일반 CFG에서는 loop의 끝이나 반복 경계가 명시적으로 잘 드러나지 않을 수 있음
- 그러나, runtime estimation에서는 loop가 매우 중요
- loop가 있는가?
- 몇 번 반복하는가?
- loop 내부 연산이 무엇인가?
-
위와 같은 것들이 runtime에 직접적인 영향을 미침
- loop end 구조를 명시적으로 드러내면
-
모델이 반복 구조를 더 쉽게 학습할 수 있음
- 즉, 원래 CFG보다 비용 추정에 유리한 형태로 구조를 정리
2.1.1.2. single-statement CFG
- 기존 CFG는 하나의 node가 여러 줄의 code block일 수 있음
- 예를 들어 한 basic block 내에 여러 statement가 들어갈 수 있음
- 그러나, 이런 경우에 node 단위가 너무 뭉뜽그려져서
- 어느 연산이 비싼지
- 어느 statement가 branch 직전인지
- 어느 부분이 loop 안에 있는지
-
를 세밀하게 관찰히가 어려움
- GRACEFUL은 code block을 쪼개서
-
statement 하나당 node 하나 수준으로 더 fine-grained 하게 표현
- 이를 통해 GNN이 더 세밀한 연산 구조를 학습할 수 있음
- 즉, 프로그램 구조를 runtime prediction에 적합한 해상도로 분할하는 것
2.1.1.3. data-flow annotation
- CFG 만으로 runtime을 예측하는 것은 매우 어려움
-
같은 코드이더라도 입력 데이터에 따라 실행 경로와 반복 횟수가 달라지기 때문
- e.g.,
if salary > 10000: expensive_func()- 위 코드의 실제 runtime은
salary > 10000인 row가 몇 개인지- expensive_func()가 얼마나 자주 호출되는지
- 에 따라 달라짐
- 위 코드의 실제 runtime은
- 일반적인 실행 환경에서는 위 코드의 runtime을 예측하기 어려우나,
- DBMS 환경에서는 기존 DBMS가 가진 통계 정보를 활용하여 위 UDF 함수의 cost estimation이 가능
2.1.1.4. cardinality
- DBMS cost model에서 cardinality는 가장 핵심적인 정보
-
연산 비용은 대체로 “몇 개의 tuple을 처리하느냐”에 크게 좌우되기 때문
- 예를 들어 join이던 filter이든
- 입력 row의 수
- 출력 row의 수
-
가 runtime에 매우 큰 영향을 줌
- 논문은 이 점을 UDF 내부에도 확장
- query plan operator에도 cardinality가 필요
- UDF 내부 data flow에도 cardinality 비슷한 정보가 필요
- 예를 들어 UDF 내부 if-branch가 존재하는 경우
- 몇 %의 row가 true branch로 갈 것인가?
- 는 사실상 UDF branch 내부 연산에 대한 cardinality 정보
2.1.1.5. UDF 내부 cardinality와 hit-ratio estimator
- DBMS는 일반적으로 query plan operator에 대해서는 cardinality estimate를 제시
- scan 결과 row 수
- join 결과 row 수
- filter 후 row 수
-
그러나, UDF 내부에 대해서는 이러한 정보가 없음
- 예를 들어, UDF 내부에
if col_a > 5: # do inexpensive something # ... else: # do expensive something # ...- 기존 DBMS에서는 UDF에
- 몇 개의 row가 if branch로 가는지
- 몇 개의 row가 else branch로 가는지
- 알려주지 않음
- 기존 DBMS에서는 UDF에
- 이를 해결하기 위해 논문은 hit-ratio estimator를 제안
- hit ratio: 특정 branch 조건이 참이 될 비율
thenbranch가 얼마나 자주 실행되는지elsebranch가 얼마나 자주 실행되는지
- 따라서, hit-ratio estimator를 통해 분기문 runtime에 대한 기대값을 계산할 수 있음
- hit ratio: 특정 branch 조건이 참이 될 비율
- hit-ratio를 어떻게 estimate할 것인가?
- UDF 내부 branch 조건을 그냥 프로그램 조건으로 두지 않음
- 가능하면 SQL predicate 형태로 변형하여 DBMS cardinality estimator에 정보를 요청
- 예를 들어, UDF 내부 조건이 테이블 컬럼 기반이면
if a > 10 and b = 'x'- 이를 SQL WHERE clause처럼 바꾸어서
- DBMS의 기존 통계 기반 caridnality estimator를 활용
- 즉, 논문은 새로운 branch selectivity 모델을 완전히 새로 만드는 것이 아니라
- 기존 DBMS의 통계 기반 추정 기능을 재활용
2.1.2. Joint Query-UDF Representation
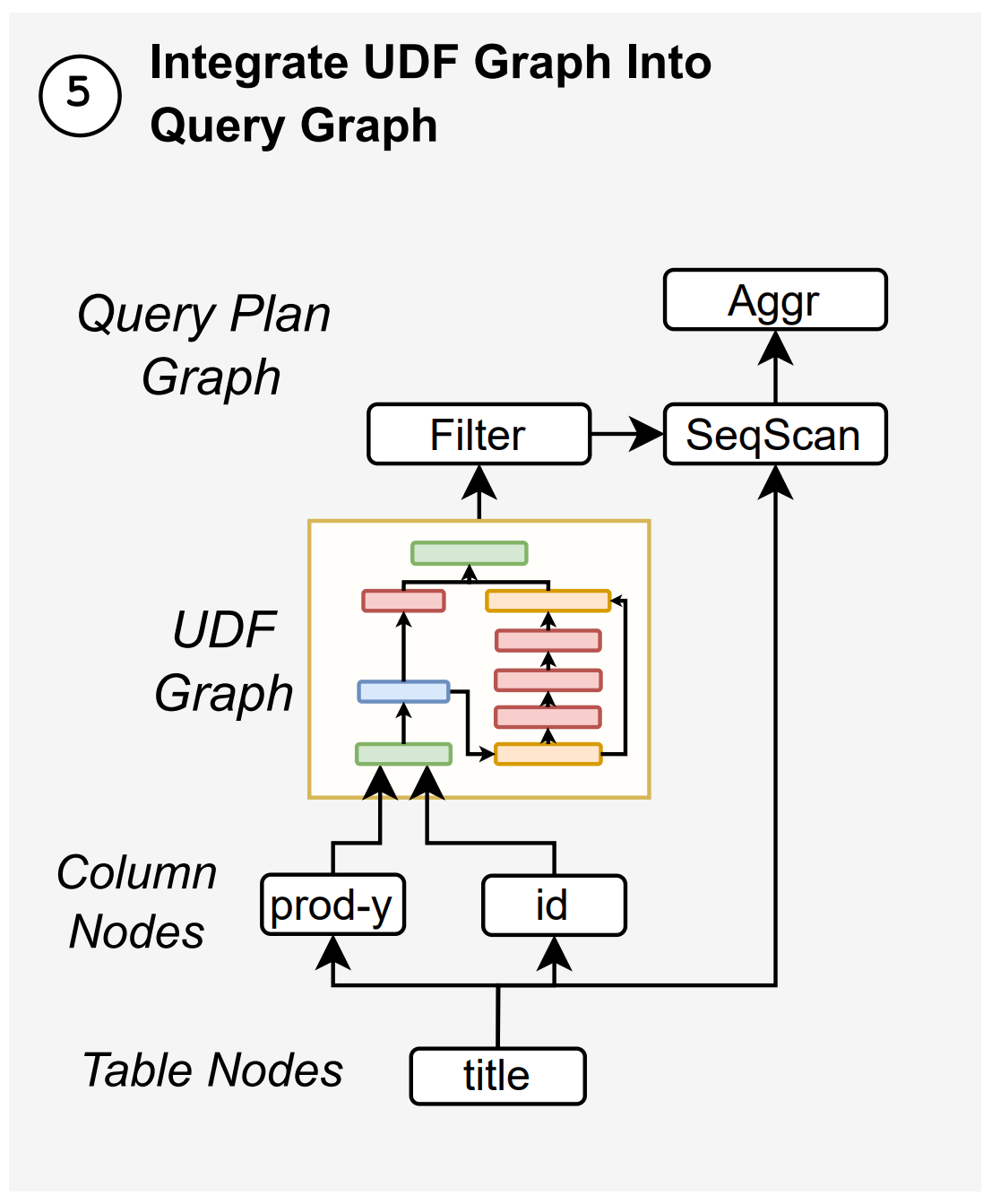
- GRACEFUL이 단순 “UDF cost estimator”가 아니라
- 정확히는 query plan runtime estimator라는 점을 보여줌
-
실제 실행 시간은 UDF만으로 결정되지 않기 때문
- runtime은 아래 조건이 모두 영향을 미침
- query plan 구조
- join order
- operator cardinality
- UDF가 plan의 어디에 위치하는지
- UDF 앞뒤 연산 결과 row 수
- UDF 내부 구조와 branch cost
- 따라서 UDF 그래프만 따로 파악하면 안 되며
-
query graph와 joint embedding을 해야 함
- 즉,
- query plan graph는 SQL 실행 구조를 표현
- UDF CFG는 함수 내부 실행 구조를 표현
- 둘을 연결하여 하나의 큰 그래프로 만들어 runtime을 찾음
2.1.2.1. query plan operator에도 cardinality annotation이 중요한 이유
- DBMS에서 동일한 join operator이어도
- 입력이 100 rows 인지
- 입력이 100M rows 인지
-
에 따라 비용이 완전 다름
- 따라서, opeartor type 뿐 아니라 입출력 cardinality가 필요
- GRACEFUL은 DBMS의 cost estimation 개념을 그대로 활용하되, UDF가 있는 경우 추가 난점이 존재한다고 주장
2.1.2.2. UDF filter가 있으면 output cardinality를 모름
- 일반적으로 filter의 output cardianlity는 selectivity로 계싼
- e.g.,
- 입력 1,000,000 rows
- selectivity 0.1 → 출력 100,000 rows
- 이때, filter predicate가 UDF인 경우 문제가 발생
- e.g.,
WHERE udf(col1, col2) <= 26026; - 위 경우, DBMS는 일반적으로
- UDF가 어떤 값 분포를 내는지
- 조건을 몇 %가 만족하는지 (i.e., selectivity)
- 를 모르기 때문에 output cardinality를 쉽게 계산할 수 없음
- 즉, plan graph에서 중요한 feature 하나가 비게 됨
- 이는 단순 cost prediction뿐 아니라 optimizer decision에도 문제를 발생시킴
- e.g.,
2.1.3. Point estimation of UDF-filter selectivity is unknown
- 일반적인 SQL filter는 예를 들어
WHERE age > 30 - 이러한 경우에 DBMS는 통계(histogram, NDV, min/max 등)을 활용해서
- 전체 row 중 몇 %가 살아남는지
- 즉, filter selectivity가 얼마인지
-
를 추정할 수 있음
- 예를 들어,
- 입력 1,000,000 rows
- selectivity 0.2
- 이면 출력은 대략 200,000 rows
-
이를 바탕으로 join, aggregation, sort 등의 비용을 계산할 수 있음
- 그러나 UDF filter는 다름
WHERE udf(a, b, c) <= 26026 - 과 같은 경우 DBMS는 아래 사항들을 알지 못함
- udf 결과값 분포가 어떠한지
- 몇 %의 row가 조건을 통과하는지
- 해당 filter를 적용한 뒤 몇 개의 row가 남을지
-
즉, UDF-filter selectivity가 unknown임
- 그러나, optimizer는 이 값을 꼭 알아야함
- selectivity가 달라지면 “push-down이 좋은지, pull-up이 좋은지”가 달라지기 때문
2.1.3.1. Solution: Predict a distribution of the costs
- GRACEFUL’s probabilistic approach:
- UDF filter selectivity가 여러 값일 가능성을 염두
- 해당 경우들에 대해 비용을 계산/예측
- 단일 cost가 아니라 cost distribution을 생성
- 즉, UDF 때문에 불확실성이 생기면, 그냥 무시하지 말고 확률적 분포로 다룸
2.1.3.2. selectivity에 따라 달라지는 cost
- 일반적인 cost model
- $\hat{C}=f(plan_features)$
-
즉, 입력 plan에 따라 cost 결과 하나를 출력
- 그러나, UDF filter가 있으면 plan의 핵심 변수가 추가되어야함
- $s=\text{UDF filter selectivity}$
- 위 비용에 따라 전체 실행 계획 비용이 달라짐
- 즉, cost model은 selectivity라는 종속 변수를 가지고 있음
- $C=C(s)$
- 예를 들어,
- $s=0.001$: 거의 다 걸러짐 → early push-down이 유리할 수 있음
- $s=0.9$: 거의 안 걸러짐 → expensive UDF를 늦게 적용하는 것이 유리할 수 있음
2.1.3.3. Iterate over the UDF-filter selectivity
- UDF-filter selectivity가 정확히 무엇인지 모르는 상황에서
- 가능한 여러 selectivity에 따른 cost estimation의 집합을 생성
- e.g., $s \in { 0.01, 0.05, 0.1, 0.2, 0.5, 0.8 }$
- 각 값에 대하여 출력 cardinality 계산
- 그 cardinality가 후속 operator에 어떤 영향을 주는지 반영
- 전체 query plan cost를 각각 예측
- 즉, 아래와 같은 형식
- ${ C(0.01), C(0.05), C(0.1), C(0.2), C(0.5), C(0.8)}$
- 위 여러 cost estimation의 집합이 cost distribution의 근사
- e.g., $s \in { 0.01, 0.05, 0.1, 0.2, 0.5, 0.8 }$
- selectivity uncertainty를 discretize해서 여러 시나리오를 평가
2.1.3.4. Cost Distribution
- cost distribution이 꼭 엄밀한 확률밀도함수(pdf)를 의미하는 것은 아님
- UDF-filter selectivity가 불확실
- 가능한 여러 경우(다양한 selectivity)에 대해 cost를 예측
- 그 결과로 cost가 어느 범위에 있을 법한지 관찰
- 예를 들어, 어떤 plan에 대해:
-
example A:
assumed selectivity predicted cost 0.01 2.1 sec 0.05 2.5 sec 0.10 3.2 sec 0.20 4.8 sec 0.50 9.7 sec 0.80 14.1 sec -
example B:
assumed selectivity predicted cost 0.01 6.3 sec 0.05 6.4 sec 0.10 6.5 sec 0.20 6.7 sec 0.50 7.0 sec 0.80 7.2 sec
-
- 위 distribution을 활용하여 아래 정보를 구할 수 있음
- cost에 대한 기댓값 (기대 비용)
- 최악 비용 (maximum predicted cost)
- 분산/불확실성
- 특정 selectivity 구간에서의 취약성
2.1.3.5. pull-up / push-down decision using cost distribution
- 2개의 후보 plan이 있다고 하자
- Plan A: UDF filter pull-up
- Plan B: UDF filter push-down
- 만약 UDF-filter selectivity를 정확히 모르면, 두 plan 중 어느 것이 좋은지 단정할 수 없음
- 예를 들어:
- selectivity가 높으면 pull-up이 좋을 수 있음
- (비싼 UDF를 초반 대량 row에 적용하는 것이 손해)
- selectivity가 아주 낮으면 push-down이 좋을 수 있음
- (초반에 많이 걸러지므로 이후 연산이 줄어듬)
- selectivity가 높으면 pull-up이 좋을 수 있음
- 따라서, plan 비교는 사실
- $C_A(s)$ vs. $C_B(s)$
-
를 비교하는 문제
-
즉, selectivity에 따라 우열이 바뀔 수 있음
- UDF는 selectivity 하나를 확정(point estimation)이 불가능 하므로
-
Graceful은 두 plan의 cost distribution을 비교
- 이에 따라:
- 기대값 기준으로 더 나은 plan
- worst-case가 더 안전한 plan
- regret이 더 작은 plan
- 등을 선택할 수 있음
2.1.4. Runtime Prediction
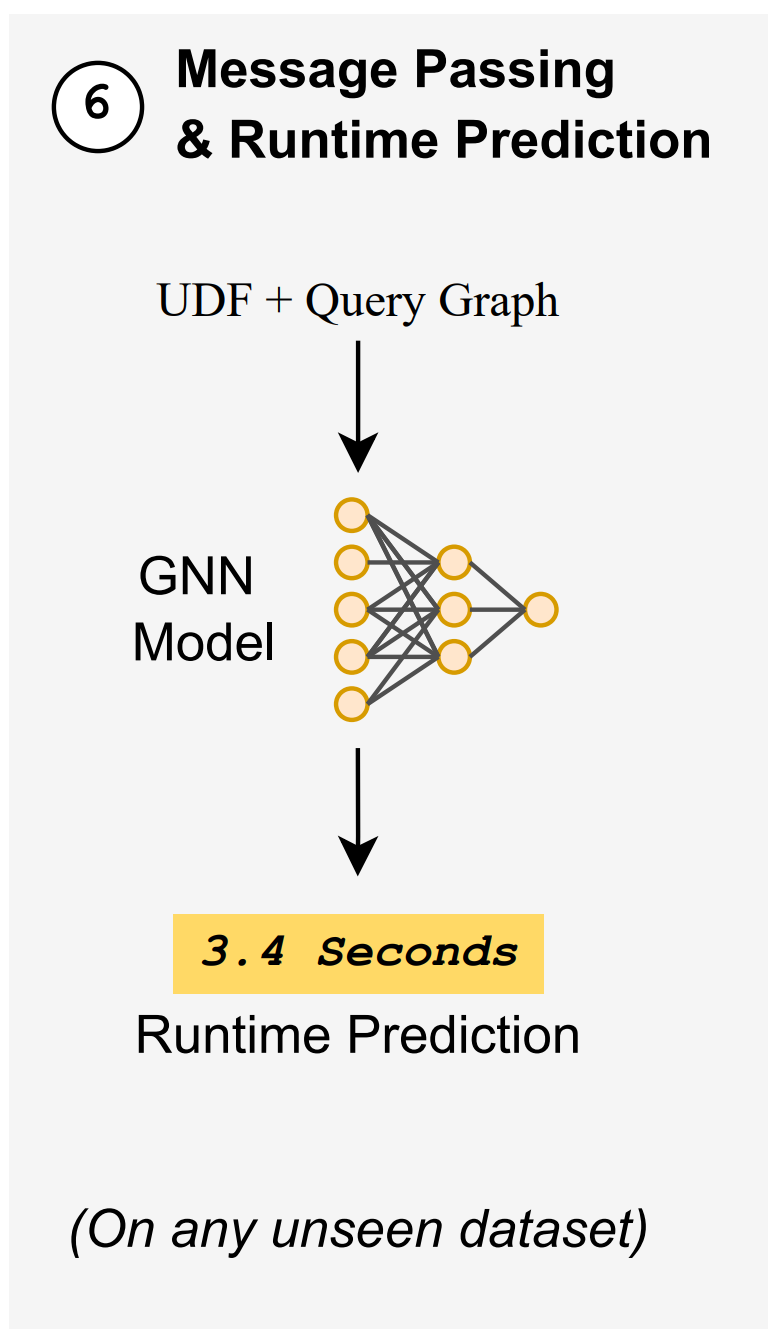
- UDF CFG와 SQL query plan을 합친 그래프를 GNN에 입력
- GNN이 생성한 graph embedding을 regression layer가 받아 query runtime을 예측
- 모델은 특정 DB나 특정 UDF에 재학습하지 않아도 zero-shot으로 동작
2.1.4.1. Joined query-UDF graph
- Query graph
- SQL query plan을 그래프로 표현
- e.g.,
scan,filter,join,aggregation과 같은 operator가 node
- UDF graph
- UDF 코드를 CFG 형태로 표현
- e.g.,
statement,branch,loop,function call등이 node
- 예를 들어, SQL plan에 아래와 같은 filter가 있다고 하자
WHERE udf(a, b) < 100 - query graph의
filternode와 UDF CFG가 연결됨 - 즉, 최종 입력은 SQL query plan graph와 UDF control-flow graph가 합쳐진 하나의 그래프
- 이를 joined query-UDF graph라고 함
2.1.4.2. Runtime prediction via GNNs
- joined query-UDF graph에는 아래 정보를 포함
- query operator 간 parent-child 관계
- UDF 내부 control-flow 관계
- branch 경로
- loop 구조
- UDF가 query plan 어디에 붙어 있는지
- opeartor cardinality
- UDF statement feature
-
따라서 일반 MLP보다 GNN이 적합
- GNN은 각 node가 주변 node와 message passing을 하면서
- 전체 그래프 구조를 반영한 representation을 학습
- 이 UDF는 어떤 구조를 가지고 있으며
- 이 query plan 안에서 어디에 위치하며
- 어느 정도 row에 대해 실행되는가?
- 를 GNN이 embedding으로 압축
2.1.4.3. Regression model as final layer
- GNN이 생성한 hidden state vector를 regression model에 입력
- regression model에서 최종 query runtime을 예측
-
추가적으로, 학습 안정화를 위해 log runtime을 예측
- 즉, pull-up / push-down classification이 아닌 run-time regression
2.1.4.4. Does this model predicts only UDF cost?
- UDF가 포함된 query plan 전체 runtime을 예측
- UDF 비용은 query context와 분리해서 생각하면 안되기 때문
- 같은 UDF이어도
- 1,000 rows에 적용되는지
- 10,000,000 rows에 적용되는지
- join 전에 실행하는지
- join 후에 실행하는지
- branch가 어느 데이터에서 자주 hit 되는지
-
에 따라 전체 비용이 달라짐
- 따라서, GRACEFUL은 UDF 단독 비용이 아닌
- query plan 내에서 UDF가 실행될 때의 전체 runtime을 예측
2.1.4.5. zero-shot manner
- 새로운 데이터베이스, 새로운 UDF, 새로운 SQL query를 사전에 학습하지 않더라도 바로 runtime을 예측
-
즉, 모델이 특정 UDF를 미리 실행하고 학습하는 방식이 아님
- DBMS optimizer에 들어가려면 zero-shot이 매우 중요
- 만약 어떤 새 UDF가 들어올 때마다
- 그 UDF를 여러 query에 대해 실행
- runtime 데이터 수집
- 모델 재학습
- optimizer가 정보 활용
-
위 과정을 거치면 실용성이 매우 떨어짐
- 실제 DBMS에서는 사용자가 임의의 UDF를 계속 만들 수 있음
- 따라서 optimizer는 처음 보는 UDF에 대해서도 즉시 판단해야함
- 즉, 기존에 본 적 없는 UDF structure, dataset, SQL query에 대해서도 코드 구조와 데이터 통계를 활용해 대략적인 비용을 예측
2.1.4.6. database-independent featurization
- feature가 특정 데이터베이스에 종속되지 않음
- 나쁜 feature의 예시는 아래와 같음
table_name = "movie_keyword" column_name = "series_years" udf_name = "my_udf_17" database_name = "imdb"- 위와 같은 feature를 사용하면 모델이 특정 DB나 UDF를 외울 가능성이 큼
- 새로운 DB에서는 작동하기 어려움
- 반면, database-independent feature (제안 논문)은 아래와 같음
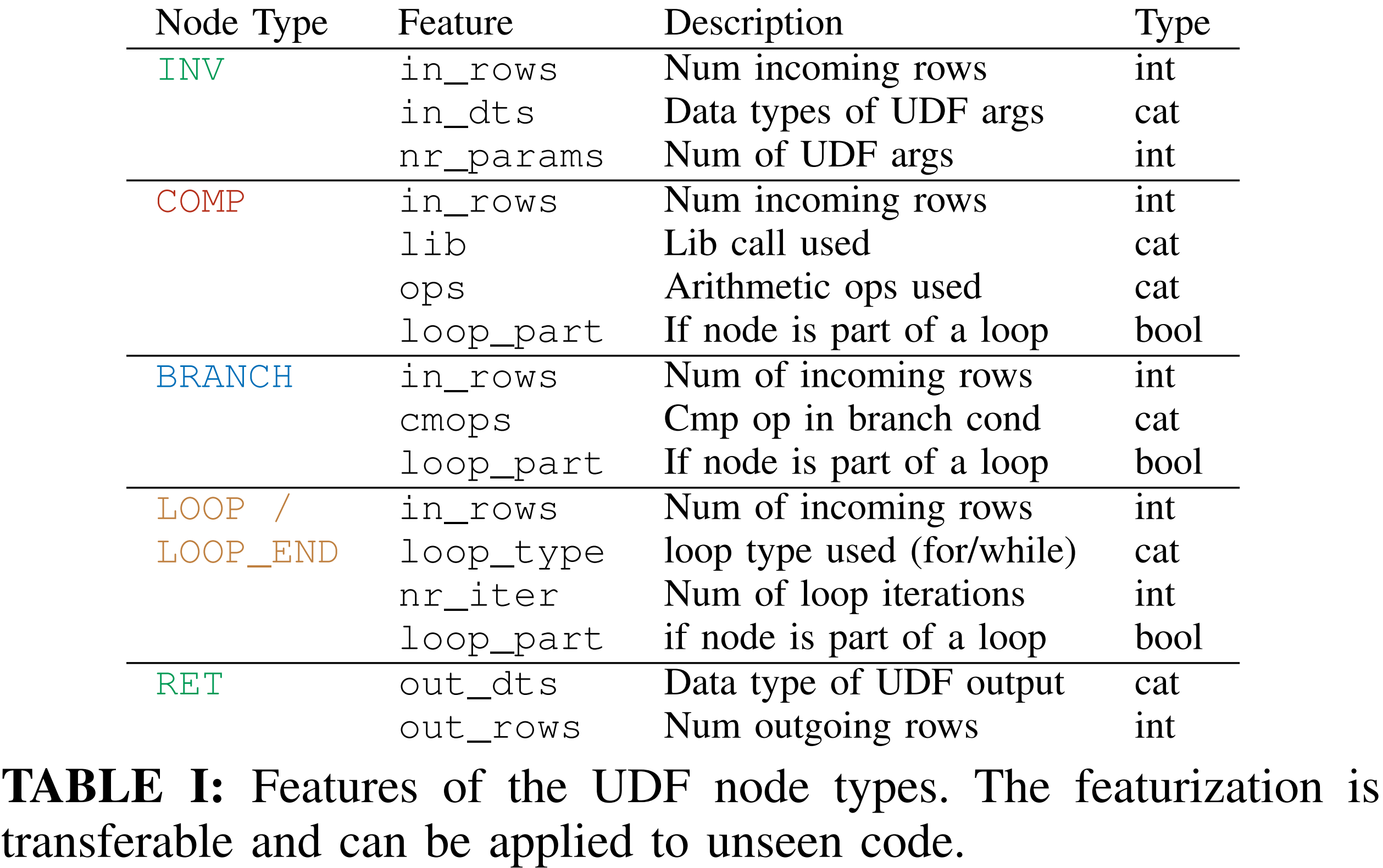
2.2. Discussion of Scope
- UDF cost estimation은 범위가 꽤 넓은 문제 정의
- scalar UDF (row-by-row)
- aggreagate UDF (group 단위, groupby 연산)
- table-valued UDF (여러 row 변환)
- vectorized UDF
- procedural UDF 등
- 이 문제들을 한 번에 다 다루면 복잡도가 폭증
- 제안 논문은 가장 기본적이면서도 중요한 케이스를 먼저 다룸
2.2.1. Scalar Python UDFs
- scalar UDF는 아래의 성질을 가짐
- 입력: 하나의 row (tuple)
- 출력: 하나의 값
- 처리 방식: row-by-row
def udf(x, y): if x > 10: return y * 2 else: return y + 1SELECT udf(col1, col2) FROM my_table;
- scalar UDF는 DBMS에서 가장 흔하게 쓰이는 형태
- filter predicate
- projection
- computed column
- feature transformation
- 특히, 이 논문에서 중요하게 생각하는 것은
- filter 내에 들어가는 UDF
- 이 경우 cost와 selectivity가 직접 연결되기 때문에 optimization 영향이 매우 큼
2.2.1.1. scalar UDF의 cost 구조
- scalar UDF의 runtime:
- $\text{total cost} = (\text{# rows}) \times (\text{cost per row})$
- 이때,
- $\text{# rows}$ → query plan cardinality에 의해 결정
- $\text{cost per row}$ → UDF 내부 구조 (loop, branch 등)에 의해 결정
- GRACEFUL은 위 두 요소를 같이 모델링
- query graph → $\text{# rows}$ (i.e., cardinality)
- UDF CFG → $\text{cost per row}$
- query graph와 UDF CFG를 결합하면 전체 runtime
2.2.1.2. UDF 내부에서 허용하는 연산 범위
- control flow
- if/else
- nested branches
- loop (for, while)
- computation
- arithmetic (덧셈, 곱셈 등)
- string operation (substring, format 등)
- external calls
mathnumpy- 기타 라이브러리
- GRACEFUL은 단순 expression이 아닌 실제 production 수준의 복잡한 UDF도 처리 가능
- 이런 복잡성이 기존 cost model이 실패하는 이유
2.2.1.3. Why Python UDF
- Python UDF는 실제 DBMS 환경에서 많이 사용됨
- 특히, analytics, ML 파이프라인
- Python은 구조 분석이 비교적 쉬움
- AST → CFG 변환이 가능
- 다양한 연산 표현 가능
- realistic workload
- 그러나, 제안 기법은 CFG 기반 표현
- parsing 과정 및 실험 구현과 별개로, 언어에 독립적인 방법론
- e.g., Python
if x > 10: y *= 2 - e.g., JAVA
if (x>10) { y *= 2; } - 위 두 코드는 언어는 다르지만 CFG는 거의 동일
- e.g., Python
- 따라서,
- parsing만 다르고
- CFG representation은 동일하게 생성할 수 있음
2.2.1.4. aggregate UDF로 확장 가능
- 예시 UDF SQL 코드
- aggregate 예시 UDF
def avg_udf_init(): return (0, 0) # (sum, count) def avg_udf_update(state, x): s, c = state return (s + x, c + 1) def avg_udf_finalize(state): s, c = state return s / c - aggregate 예시 SQL
SELECT avg_udf(col) FROM table GROUP BY key;
- aggregate 예시 UDF
- aggregate UDF의 실행 단계
- INIT (state 초기화)
group A → state = (0, 0) group B → state = (0, 0) group C → state = (0, 0) - UPDATE (핵심 반복 단계)
- 각 row를 읽으면서 state 갱신
-
예:
key col A 10 A 20 B 5 - 처리 과정
row (A,10): state_A = (0,0) → (10,1) row (A,20): state_A = (10,1) → (30,2) row (B,5): state_B = (0,0) → (5,1)즉, $state \leftarrow f(state, row)$
- FINALIZE (결과 생성)
- 모든 row를 처리한 뒤 state를 결과로 반환
state_A = (30,2) → 15 state_B = (5,1) → 5
- 모든 row를 처리한 뒤 state를 결과로 반환
- INIT (state 초기화)
- aggregate 연산의 state 유지
- scalar UDF: $\text{row} \rightarrow f(\text{row}) \rightarrow \text{output}$
- row 하나 처리
- aggregate UDF: $\text{state0} \rightarrow \text{update} \rightarrow \text{state1} \rightarrow \text{state2} \rightarrow \cdots \rightarrow \text{finalize}$
- 이전 계산 결과(state)가 다음 계산에 영향을 미침
- aggregate 연산은 본질적으로 “누적 계산”
구분 scalar UDF aggregate UDF 입력 row 1개 여러 row 출력 값 1개 값 1개 적용 방식 row-by-row group-by 단위 cost 구조 N × per-row cost group size + state update - scalar UDF: $\text{row} \rightarrow f(\text{row}) \rightarrow \text{output}$
- group size가 cost에 미치는 영향
- scalar UDF cost
- $\text{cost} \approx N \times c_{\text{per-row}}$
- aggregate UDF cost
- $\text{cost} \approx \sum_{group}(\text{group size}) \times c_{\text{update}} + c_{\text{finalize}}$
- scalar UDF cost
- aggregate UDF가 더 어려운 이유
- 상태(state) 유지
- group size에 따라 cost가 다름
- partial aggregation, merge 단계 존재
-
즉, 단순히 (per-row cost) × (# rows)가 아님
- 제안 아이디어
- CFG에 aggregation operation을 명시
- aggregation state node
- update operation node
- merge operation node
- CFG에 aggregation operation을 명시
2.2.2. Non-UDF Queries
2.2.2.1. 왜 Non-UDF Query가 중요한가
- 현실 DBMS workload:
- 어떤 query는 UDF가 존재
- 어떤 query는 UDF 미존재
- 예:
- 일반 SQL
SELECT * FROM orders WHERE price > 100; - UDF 포함 SQL
SELECT * FROM orders WHERE udf(price, discount) > 100;
- 일반 SQL
- 실제 optimizer는 두개 모두 처리해야함
- 만약 GRACEFUL이 UDF query만 잘 수행하고 일반 query에서는 성능이 나쁘다면
- 실제 DBMS에 적용하기 어려움
- 따라서, GRACEFUL은 일반 query도 최적화 가능하도록 설계
2.2.2.2. Non-UDF Query 최적화가 가능한 이유
- GRACEFUL의 기본 입력: query plan graph
- UDF가 포함된 경우 GRACEFUL의 입력: query plan graph + UDF CFG
- 즉, UDF가 없는 경우에는 “UDF subgraph가 비어 있는 special case”
- Query Operator Modeling은 아래 논문의 learned cost estimation 모델 사용
- B. Hilprecht and C. Binnig, “One model to rule them all: Towards zero-shot learning for databases,” CIDR 2022
2.2.2.3. Query Representation
- 일반 query plan
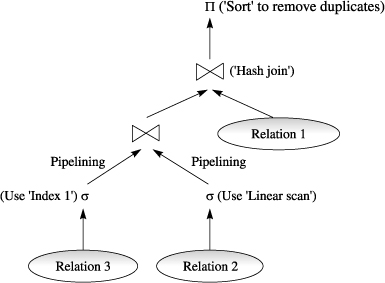
-
GRACEFUL은 각 operator를 graph node로 표현
operator feature Scan estimated rows Filter selectivity Join join type Aggregation group cardinality -
즉, 일반 query optimization용 learned model 구조를 그대로 활용
- 그러나, GRACEFUL은 여기에 UDF internal structure를 CFG로 표현하여 추가
- branch
- loop
- arithmetic
- string op
- library call
- hit-ratio
- 위와 같은 UDF semantics를 grpah로 넣음
- 즉, GRACEUFL의 입력 graph는 (query plan graph + UDF CFG)
- 또한, GRACEFUL은 non-UDF 또한 high accuracy를 달성
- 만약 UDF를 지원하기 위해
- 일반 query 성능이 나빠지거나
- inference가 지나치게 느려지면
- DBMS 전체 optimizer로 활용하기 어려움
- 만약 UDF를 지원하기 위해
3. GRACEFUL Design
- 논문 구조
- 3.1. UDF Representation: UDF를 어떻게 graph로 표현할 것인가
- 3.2. branch/loop가 실제 데이터에서 얼마나 실행될지(hit-ratio, cardinality)를 어떻게 추정할 것인가
- 3.3. UDF graph와 query plan graph를 어떻게 합칠 것인가
- 3.4. GNN을 어떻게 학습하고 inference할 것인가
3.1. UDF Representation
- query 내 UDF 코드를 어떻게 graph로 표현할 것인가
- graph의 node type과 feature는 무엇인가
- UDF featurization과 query plan information이 어떻게 통합되는가
3.1.1. Control-Flow Graph as Basis
-
GRACEFUL의 UDF 표현의 핵심 구조(backbone): CFG(Control Flow Graph)
-
CFG
def my_func(i, numbers): if i < len(numbers): return numbers[i] % 2 == 0 return None
- 즉,
- node: 코드 블록(statement/block)
- edge: 실행 흐름
- 왜 CFG를 사용하는가?
- runtime은 단순히 코드 길이로 결정되는 것이 아님
- e.g.,
def my_func(in_col): for i in range(20): # do something for j in range(300): # do something if (condition1): # do something else: # do something # do something while (condition2): while (condition3): # do something - 위와 같은 control flow 구조를 그래프로 표현하면 전체 코드 구조를 파악하기에 용이
- 따라서, 전체 runtime을 예측하기에 용이
- e.g., if branches, loop condition, nested loops, …
- 즉, $\text{runtime} \sim \text{execution path}$
- CFG는 어떻게 생성?
- 기존 Python CFG 생성 도구(
python_graphs)를 활용하여서 - standard CFG를 우선 생성
- 기존 Python CFG 생성 도구(
- CFG node types
- computation node
x = y + z- 와 같은 계산 코드
- control-flow node
if else for while return try except- 와 같은 실행 흐름 제어 코드
- computation node
- basic block
- 중간에 branch 없이 연속 실행되는 코드 묶음
- e.g.,
a = x + y b = a * 2 c = b - 1 - 위와 같은 예시는 하나의 basic blcok
- 중간에 jump 없음
- 조건 분기 없음
- edge
- 가능한 모든 실행 경로
- 즉, 다음에 실행 가능한 코드
- e.g.,
if x > 10: A else: B - 실행 가능한 모든 경로이기 때문에 각 branch마다 edge 존재
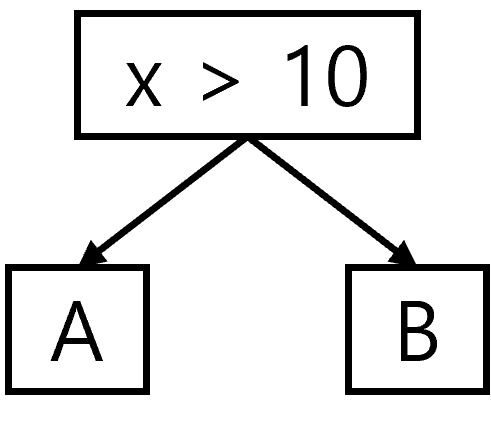
- CFG extension in GRACEFUL
- GRACEFUL은 standard CFG에서 extension을 수행
- 단순 코드 흐름 뿐 아니라
- 데이터 흐름(data flow)도 graph에 포함
- UDF runtime은 코드만으로 결정되는 것이 아니기 때문
- e.g.,
def udf(price): if price > 1000: # do expensive things else: return price- 즉, if가 얼마나 얼마나 자주 true인지
- price distribution이 어떠한지
- 에 따라 udf cost가 달라짐
- 따라서, $\text{runtime_estimator}(\text{code_structure})$ 만으로는 충분하지 않음
- $\text{runtime_estimator}(\text{code_structure}, \text{input_data_distribution})$ 두 입력이 필요
- connect UDF nodes with column nodes
- query plan 내의 column 정보를 UDF graph와 연결
- 이를 통해 input column의 distribution 정보를 UDF CFG에 주입
- 이를 위해 column node를 추가
- column node: UDF의 입력으로 사용되는 컬럼에 대한 정보를 표현
- Main Contribution
- 기존 방식: UDF = black box
- GRACEFUL: query plan + input data + code structure
- 즉, (query graph, column statistics, UDF CFG)를 함께 모델링
- 일반적인 프로그램의 runtime prediction보다 DBMS runtime prediction이 할 수 있는 것이 더 많은 이유
- 일반적인 프로그램: 입력 데이터의 분포를 모름
- UDF: DBMS의 Statistics를 활용할 수 있음
- histogram
- cardinality
- selectivity
- …
- 또한, 최적화 관점에서도 DBMS에서 할 수 있는 것이 더 많음
- 일반적인 프로그램: Imperative Language
- Imperative: 작업을 어떻게 수행할지 상세히 명세
- 중간 결과를 함부로 수정하기 힘듦
- SQL: Declarative Language
- Declarative: 무엇을 원하는지 명세
- 최종 결과가 동일하게 나오는 보장 하에 query plan 변경이 더 용이
- 일반적인 프로그램: Imperative Language
3.1.2. Transforming the CFG
3.1.2.1. Transform Loop to DAG(Directed Acyclic Graph)
- 일반적인 CFG
- 일반 CFG에서 loop는 cycle을 생성
- e.g.,
x = 0 for i in range(10): x += i - 일반적인 CFG는 아래 처럼 다시 loop condition으로 돌아가는 cycle이 존재
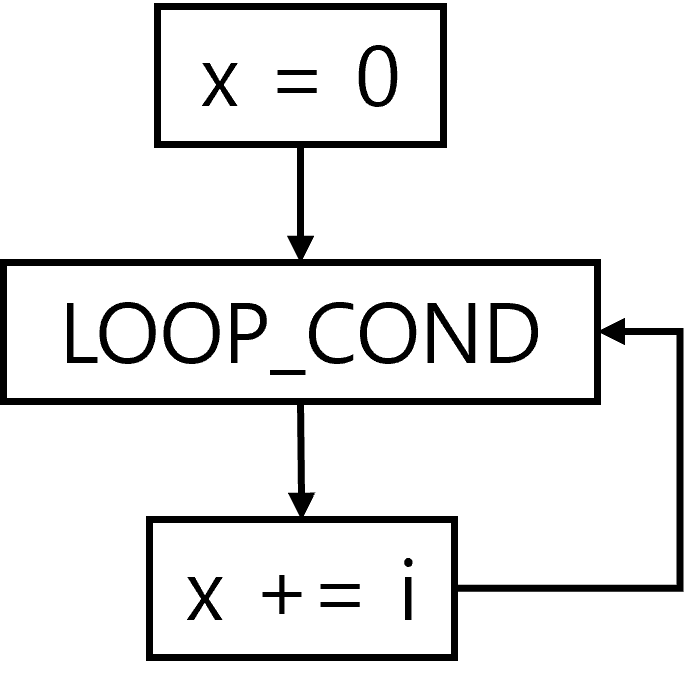
- 그러나, GRACEFUL은 CFG를 DAG로 변환
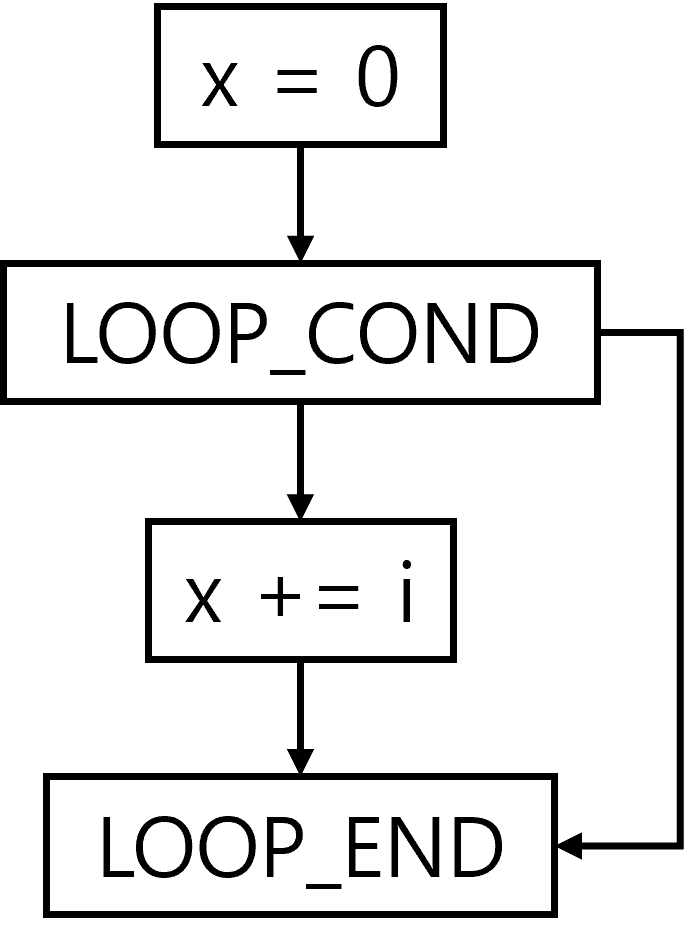
- 즉,
- 실제 반복 구조(cycle) 제거
LOOPnode와LOOP_ENDnode 추가- 반복 횟수는 feature로 저장
- 이를 통해 그래프를 DAG로 변환하면 GNN 학습이 용이함
3.1.2.2. Basic Block을 세분화 하여 Single-Statement CFG 생성
- 일반 CFG에는 여러 연산이 하나의 basic block에 들어갈 수 있음
x = math.sin(a+b) * c
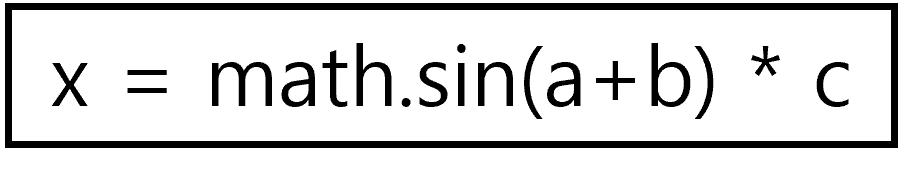
- GRACEFUL은 이를 더 세밀하게 나눔
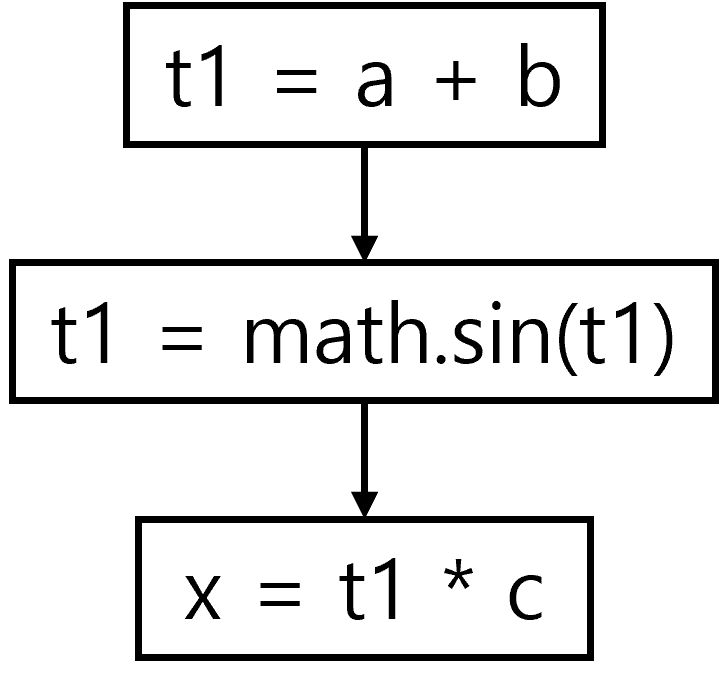
3.1.2.3. Basic Block을 세분화 하는 이유
- 아래 두 UDF를 생각해보자
x = a + bx = np.linalg.inv(A) - 두 코드 모두 CFG에서는 단순 computation node일 수 있음
- 하지만 실제 비용 차이는 상당함
- 따라서,
computation노드 하나로 구분하지 않고 +,np.linalg.inv,math.sin,string concat과 같은 연산을 분리하여 표현해야 GNN이 비용 차이를 학습할 수 있음
3.1.2.4. 그러나, 모든 연산을 다 분해하지는 않는다
- 예를 들어,
x = a + b * c - d - 를 완전히 분리하면
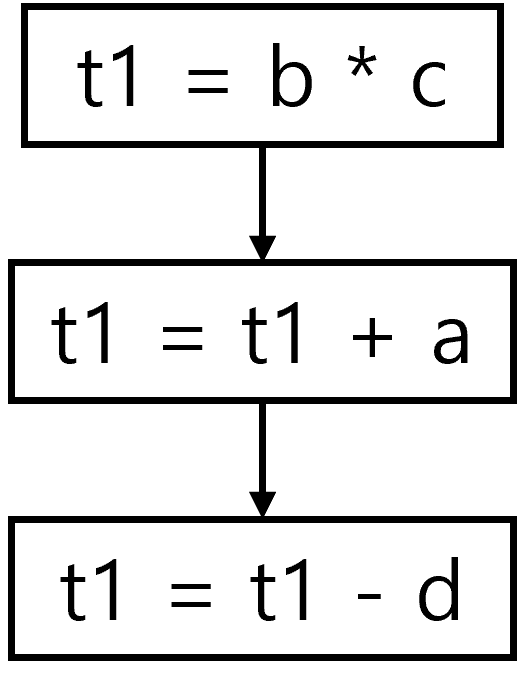
- 처럼 노드 수가 계속 증가
- UDF가 길어질 수록 그래프의 크기가 급증
- 따라서 제안 논문은 같은 코드 라인 내의 단순 arithmetic 연산은 하나의 노드로 유지
-
즉,
a + b * c - d와 같은 arithmetic 연산은 하나의 computation node로 유지 - 반면,
np.sin(...) math.log(...) - 같은 nested function call은 별도 node로 분리
3.1.3. Handling Loops
3.1.3.1. 기본 아이디어: loop를 DAG로 표현
- 일반적인 CFG
- 일반 CFG에서 loop는 cycle을 생성
- e.g.,
x = 0 for i in range(10): x += i - 일반적인 CFG는 아래 처럼 다시 loop condition으로 돌아가는 cycle이 존재
- 그러나, GRACEFUL은 CFG를 DAG로 변환
- 즉,
- 실제 반복 구조(cycle) 제거
LOOPnode와LOOP_ENDnode 추가- 반복 횟수는 feature로 저장
- 이를 통해 그래프를 DAG로 변환하면 GNN 학습이 용이함
3.1.3.2. loop_part flag
- loop 내 모든 operator에
loop_partflag를 설정 - 예를 들어,
a = 0 b = 1 for i in range(n) a += i b *= 2
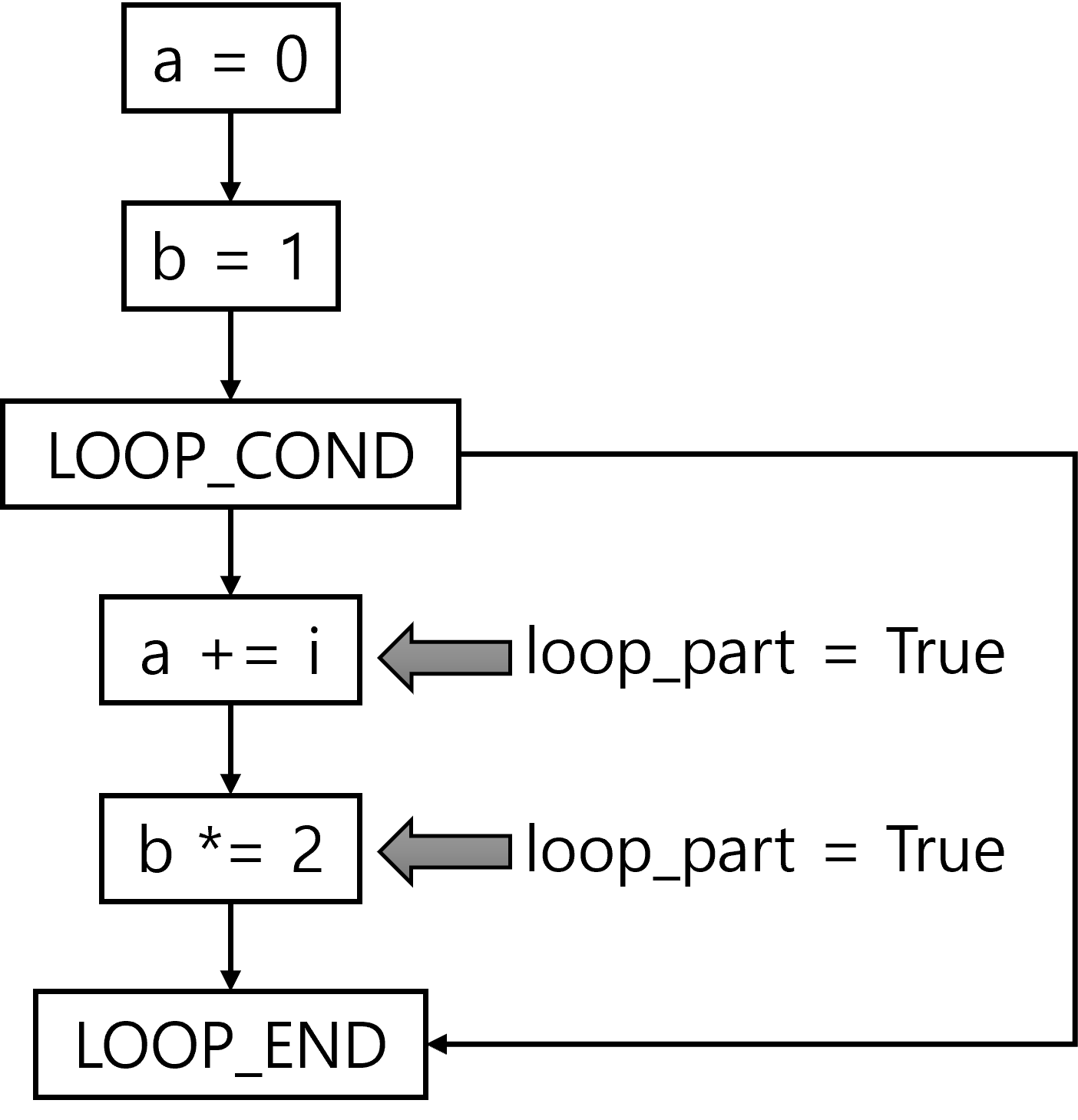
- 즉, loop 내 node에는 `loop_part = True’ flag를 삽입
- GNN이 반복 수행되는 연산을 인식하도록 하는 것
3.1.3.3. Problem Situation 1: propagation of loop information diminish
- 예를 들어, 아래와 같은 코드가 있다고 하자
for i in range(1000): temp = func1(my_input) temp = func2(temp) temp = func3(temp) temp = func4(temp) # ... temp = func5(temp) - 위 상황에서
LOOP_END노드와shortcut edge없이 생성되는 그래프는 아래와 같음

- GNN은 위 그래프에서 message passing을 수행
- 이때,
LOOP노드에서 op100까지의 거리가 너무 멀어짐 - 따라서,
LOOP의 정보가 op100까지 잘 전달되지 않음- 즉, loop 관련 정보가 희석됨
3.1.3.4. Proposing Solution 1: LOOP_END node
- 일반적인 CFG에는
LOOP_END와 같은 노드가 없음 - 그러나 GRACEFUL은 의도적으로 생성
- loop 전체를 하나의 영역으로 명시적으로 표현하기 위함

- 그러나 여전히
LOOP와LOOP_END사이 거리가 멀음
3.1.3.5. Proposing Solution 2: shortcut edge
- 따라서, shortcut edge를 추가
- GNN 관점에서 원래는:
LOOP -> func1 -> func2 -> ... -> func100 -> LOOP_END로 - message passing을 100번 해야함
- GNN 관점에서 원래는:
- 그러나, shortcut edge 추가 후에는
LOOP -> LOOP_END로 한 번에 전달됨
- 즉,
LOOP_END는- loop 내부 정보:
- func1 ~ func100
- loop 자체 정보:
- loop type
- interation count
- 정보를 동시에 가짐
- loop 내부 정보:

3.1.3.6. Fusing of loop-related information
- UDF의 root node(
RETURNnode)에 모든 정보를 모아서 embedding을 생성하는 것이 중요 - 아래 두 정보를 fusing
- loop-related information
- type of the loop
- code execution inside the loop
- pre-loop computation
- loop-related information
- 이때,
LOOP_END노드가 해당 loop의 요약본 역할을 하여RETURN노드에 최종 정보를 요약하는데 도움
3.1.4. Various UDF Node Types
- GRACEFUL은 모든 코드를 그대로 노드로 만들지 않음
- 실행 비용(runtime)에 영향을 주는 요소들만 추상화하여 5개의 노드 타입으로 표현
- COMP (Computation)
- BRANCH
- LOOP
- INV
- RET (Return)
3.1.4.1. COMP (Computation) node
- 계산 연산을 나타내는 노드
- e.g.,
x + y x * y np.sin(x) mat h.log(x) -
위와 같은 연산들을 표현
-
예를 들어,
a = b + c이면COMP(+)노드를 생성 - 아래 node feature를 가짐
- in_rows: number of incoming rows, (integer)
- lib: library call used, (categorical)
- ops: arithmetic operators used, (categorical)
- loop_part: Is this node part of a loop, (boolean)
3.1.4.2. BRANCH node
- 조건 분기를 표현
- e.g.,
if x > 10: # do something -
그래프에서는
BRANCH(>)처럼 표현 - 아래 node feature를 가짐
- in_rows: number of incoming rows, (integer)
- cardinality estimator 활용
- cmops: comparison operators in branch condition, (categorical)
- loop_part: Is this node part of a loop, (boolean)
- in_rows: number of incoming rows, (integer)
3.1.4.3. LOOP / LOOP_END node
- 반복문을 표현
- e.g.,
for i in range(10): # do somethingwhile x > 10: -
그래프에서는
LOOP로 표현 - 아래 node feature를 가짐
- in_rows: number of incoming rows, (integer)
- loop_type: used loop type, i.e., for/while, (categorical)
- nr_iter: number of loop iterations, (integer)
- loop_part: Is this node part of a loop, (boolean)
3.1.4.4. INV node
- UDF 호출을 표현
- e.g.,
SELECT udf(t1.col1) FROM mytable AS t1; - 이는 아래의 호출 과정을 거침
- for each row:
- DB engine extracts each parameter’s column value
- Switch context to python runtime
- Execute python scalar-UDF
- Return to DB engine
- for each row:
- 이때,
- 함수 호출
- 함수 인자 전달
- type conversion
- 등의 비용이 발생
- 이를 INV node로 표현
3.1.4.5. RET node
- UDF 결과 반환을 표현
- e.g.,
return x - 이는 아래의 연산 과정이 필요
- Convert python return value type to DBMS type
- Save UDF result to DBMS temporary table
- 이때,
- e.g.,
(1)return 1 - e.g.,
(2)return large_string (1)보다(2)가 더 비쌀 수 있음
- e.g.,
- 이를 RET node로 표현
3.1.5. Transferable Featurization
3.1.5.1. 왜 Transferable Featurization이 필요한가?
- 논문이 지적하는 문제점: “거의 모든 UDF는 서로 다르다”
- e.g.,
def udf1(x): return x + 1def udf2(price): return np.log(price)def udf3(name): return name.upper()def udf4(a,b): if a > b: return a return b - 일반적인 ML 관점에서 생각하면
Training: UDF1 UDF2 UDF3 ... Inference: UDF99999 - 와 같은 상황
- 즉, “훈련 때 본 적 없는 코드”(unseen code)를 처리할 수 있어야 함
3.1.5.2. 무엇을 학습하는가?
- 논문의 핵심 아이디어:
- 코드 자체 -> X
- 코드의 복잡도 특성 포착 -> O
- e.g.,
x + ya + b - 위 두 연산은
- 변수 명은 다르지만
- 덧셈 연산이라는 특징은 동일
- GRACEFUL은 이런
- 연산 종류
- 분기 종류
- 반복 구조
- 데이터 타입
- 입력 행 수
- 을 input feature로 사용
3.1.5.3. 가장 중요한 feature: in_rows
-
in_rows는 거의 모든 node가 갖는 feature - e.g.,
SELECT * FROM mytable as t1 WHERE udf(t1.col1) < 100000; - 만약 100 rows에 대해 UDF를 실행하면
- UDF는 100번 호출
- 만약 10,000,000 rows에 대해 UDF를 실행하면
- UDF는 10M번 호출
-
즉, $\text{runtime} \propto \text{# rows}$ 인 경우가 많음
- 특히, loop의 경우
for i in range(100): expensive_func()- 와 같은 반복문이 있다면
- 100 rows ->
expensive_func()를 총 10,000번 호출 - 10,000,000 rows ->
expensive_func()를 총 1,000,000,000번 호출
- 100 rows ->
- 두 실행 간에는 비용 차이가 큼
- 와 같은 반복문이 있다면
- 또한, branch의 경우
if price > 100: ret_val = expensive_func() return ret_val else: return price- 위와 같은 상황에서는 몇 개의 row가
- if branch를 통과하는지
- else branch를 통과하는지
- 중요함
- 위와 같은 상황에서는 몇 개의 row가
- 따라서 이를 cardinaltiy estimator를 활용하여 추정한 후
- node feature(
in_rows)에 삽입
3.1.5.4. Arithmetic / String Operation Encoding
- Operator 종류를 one-hot vector로 표현
- e.g.,
a + b:ADD-> [1, 0, 0, 0]a * b:MUL-> [0, 1, 0, 0]a / b:DIV-> [0, 0, 1, 0]name.upper:STRING_OP-> [0, 0, 0, 1]
3.1.5.5. Encoding Library Call
- Library Call 또한 one-hot encoding
- e.g.,
- lib = math
math.sin(x) - lib = numpy
np.log(x) - lib = string
str.upper(x)
- lib = math
- 위와 같은 예씨를 one-hot vector로 표현
3.1.5.6. if-else branch prediction using cardinality estimator
- concrete literal은 사용하지 않음
- e.g.,
if age > 30:- 이때,
30은 feature로 사용하지 않음
- 이때,
- 다른 DB에서는
if salary > 30000:- 일 수도 있음
-
즉,
30,30000,5000과 같은 숫자는 일반화가 어려움 - GRACEFUL은 비교연산자와 cardinality를 node feature로 사용
- 비교 연산자:
<,>,==,!= - cardinality: 몇 개의 row가 branch를 통과하는가
- 비교 연산자:
- e.g.,
if age > 30: # do something - 을 아래 SQL로 변환
SELECT COUNT(*) FROM mytable as t WHERE t.age > 30; -
이후 cardinality estimator를 활용하여 몇 개의 row가 branch를 통과하는지 추정
- 이를 통해,
age > 30과salary > 100000모두 80% rows가 branch를 통과한다는 selectivity 정보를 얻을 수 있음
3.1.5.7. INV node feature
- input argument의 변수명은 무시
-
대신, 인자 개수와 데이터 타입을 node feature로 저장
- e.g.,
def udf(price, quantity): return None - 변수명
price와quantity는 무시 - 대신, 인자 개수와 데이터 타입을 node feature로 저장
- 인자 개수:
nr_params = 2 - 데이터 타입:
int, int
- 인자 개수:
- UDF 호출 비용은
- argument 개수
- argument datatype
- 에 영향을 받기 때문에 위 정보를 저장
3.1.5.8. RET node feature
-
반환형도 마찬가지
- e.g.,
return 123out_dts = int - e.g.,
return "very long string"out_dts = string - 이유는 Python datatype에서 DB datatype으로의 변환 비용이 datatype에 따라 달라지기 때문
3.1.5.9. Summary about transferable featurization
- SQL+UDF에서
- 변수명
- 함수명
- literal 값
-
과 같은 UDF마다 달라지는 정보는 삭제
- 아래와 같은 비용 관련 특성만 feature로 사용
- 연산 종류
- 분기 종류
- 반복 구조
- 입력 row 수
- datatype
- library call
- 따라서, GRACEFUL은
- unseen SQL+UDF에서도 비용 추정을 수행할 수 있음
- 즉, 이 부분이 zero-shot generalization의 핵심 부분
3.2. UDF Selectivity Annotation
3.2.1. Hit-Ratios Estimation / Branch Prediction
3.2.1.1. Problem Situation
- 문제 상황: 같은 UDF라도 tuple마다 비용이 다를 수 있다
- e.g.,
def udf(x): ret_val = x if x < 10: ret_val += 1 else: for i in range(1000): ret_val += i return ret_val- 입력이
x = 1이면+한 번만 수행 - 입력이
x = 42이면 1000번 loop를 반복 수행 - i.e., 같은 UDF이어도 tuple별 비용이 다름
- 입력이
- 따라서 runtime은 단순히
UDF 구조만으로는 알 수 없음
3.2.1.2. The things we need to know: Hit-Ratios (Seletivities)
- if branch는 몇 개의 row가 통과하고 else branch는 몇 개의 row가 통과하는가?
- e.g.,
if age > 30:- 위 조건이 전체 100만 rows 중, 80만 rows가 조건을 만족한다면
-
hit-ratio = 0.8 - 반대로, 20만 rows가 조건을 만족한다면
hit-ratio = 0.2
-
i.e., $\text{hit ratio} = \frac{\text{# rows that satisfies if condition}}{\text{# total rows}}$
- GRACEFUL은 hit-ratio를 추정하기 위해 우선 UDF branch 조건을 SQL WHERE-clause로 변환
SELECT * FROM mytable WHERE age > 30; - 이후,
ANALYZE질의롤 통해histogram,MCV,cardinality statistics정보를 획득 - 마지막으로 DBMS cardinality estimator를 활용하여
- 해당 조건을 만족하는 row가 몇 개 존재하는지 파악
- 이때, GRACEFUL은 가능한 모든 경로에 대해 조건들을 검사
- e.g.,
- 주어진 소스 코드
if age > 30: # do something if salary > 100000: # do something else: # do something else: # do something - 모든 가능한 경로를 추적
- 가능한 경로는 아래와 같음
- Path 1
age > 30 & salary > 100000 - Path 2
age > 30 & salary <= 100000 - Path 3
age <= 30
- 이후 모든 경로에 대해 SQL로 변환
- Path 1
SELECT * FROM employee WHERE age > 30 AND salary > 100000; - Path 2
SELECT * FROM employee WHERE age > 30 AND salary <= 100000; - Path 3
SELECT * FROM employee WHERE age <= 30;
- Path 1
- Cardinality Estimator를 활용하여 Hit-Ratio 추정
- WHERE-clause filter를 적용하지 않았을 때의 해당 table의 전체 row 측정
- 각 경로에 대해 변환된 SQL을 활용하여 Cardinaltiy 추정
- $\text{hit-ratio}=\frac{\text{estimated cardinality}}{\text{total row}}$
- 주어진 소스 코드
- 또한, joins before UDF도 포함
- e.g.,
SELECT * FROM A JOIN B ON col1 WHERE A.x > 10 AND udf(B.y) <= 100000;if B.y > 100: # do something - 이때, 해당 execution plan에서
JOIN B on col1과WHERE A.x > 10clause가 먼저 실행된다면- Cardinality Estimation(Hit-Ratio Estimation)을 위한 SQL은 아래와 같음
SELECT * FROM A JOIN B ON col1 WHERE A.x > 10 AND B.y > 100;
- Cardinality Estimation(Hit-Ratio Estimation)을 위한 SQL은 아래와 같음
- 그렇지 않고
udf(B.y) <= 100000이 가장 먼저 실행된다면- Cardinality Estimation(Hit-Ratio Estimation)을 위한 SQL은 아래와 같음
SELECT * FROM B WHERE B.y > 100;
- Cardinality Estimation(Hit-Ratio Estimation)을 위한 SQL은 아래와 같음
3.2.1.3. DAG가 중요한 이유
- CFG의 loop cycle이 그대로 있으면
-
가능한 path 수가 무한대가 될 수 있음 (path enumeration)
- GRACEFUL은 CFG를 DAG로 변환
- 따라서, 가능한 execution path 수가 유한해짐
- 모든 path에 대해
- hit-ratio를 계산할 수 있음
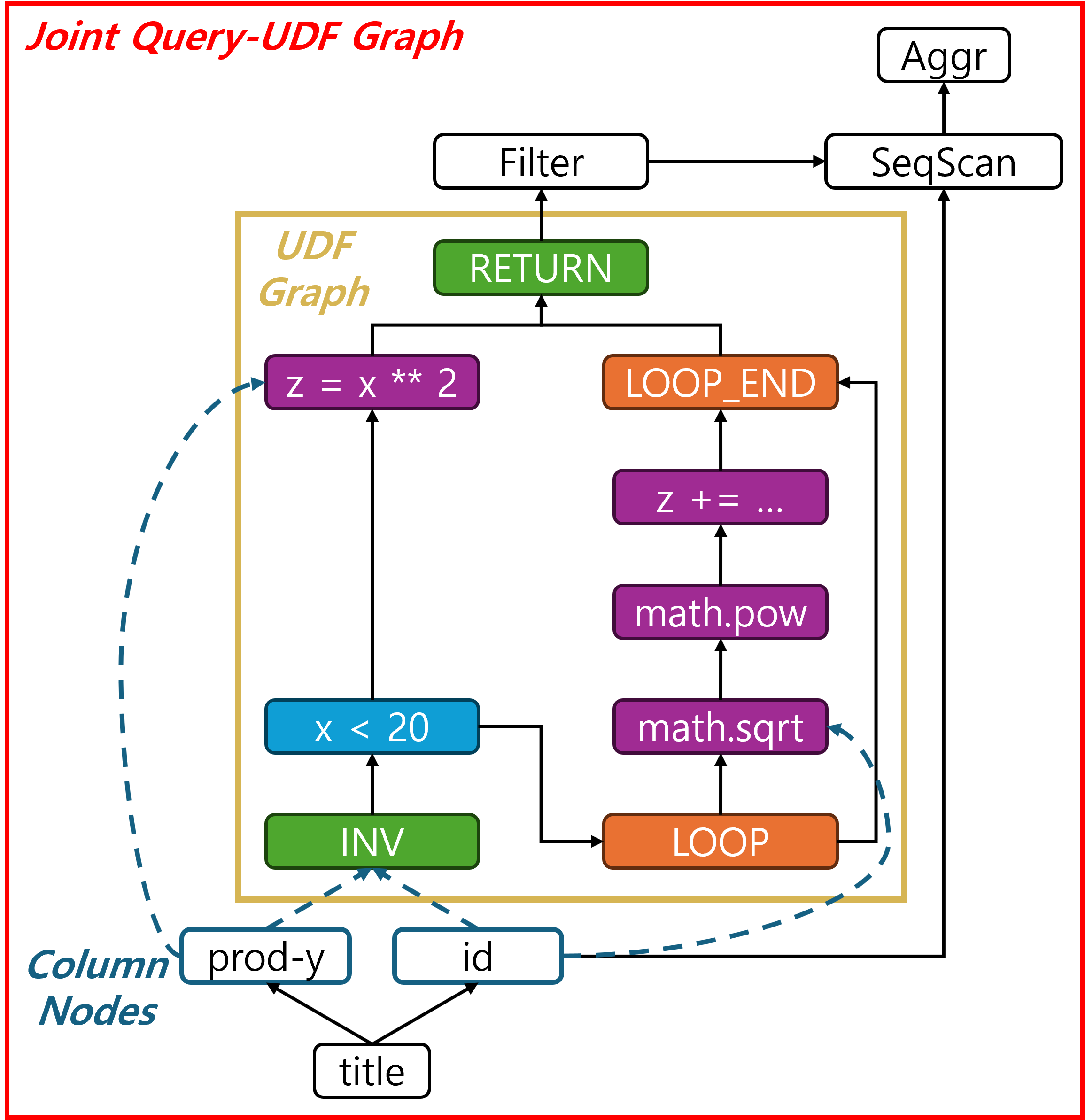
3.3. Joint Query-UDF Representation
- GRACEFUL은
Query Plan Graph와UDF Graph를 하나로 합쳐서 표현- SQL UDF 비용은 UDF 코드만으로 결정되지 않기 때문
- Joint Query-UDF Representation
- SQL Query Plan Graph
- UDF CFG Graph
- 위 두 Graph를 합쳐서 Joint Query-UDF Representation 생성
3.3.1. 왜 UDF만 표현하면 안되는가?
- 예를 들어, 동일한 UDF가 있다고 하자
def udf(x): for i in range(100): x += i return x - 그러나, Query에 따라,
- Plan A:
10,000 rows -> UDF - Plan B:
10 rows -> UDF
- Plan A:
- 따라서, GRACEFUL은 UDF 그래프와 Query Plan 그래프를 연결해서 하나의 큰 그래프로 생성
3.3.2. UDF 그래프와 Query Plan 그래프 결합
- 예를 들어, 아래와 같은 SQL과 UDF가 주어졌다고 하자
- SQL
SELECT COUNT(*) FROM title WHERE func(title.production_year, title.id) > 5; - UDF
def func(x, y): if x < 20: z = x ** 2 else: for i in range(100): z += math.pow(math.sqrt(y), i) return z - Query Graph
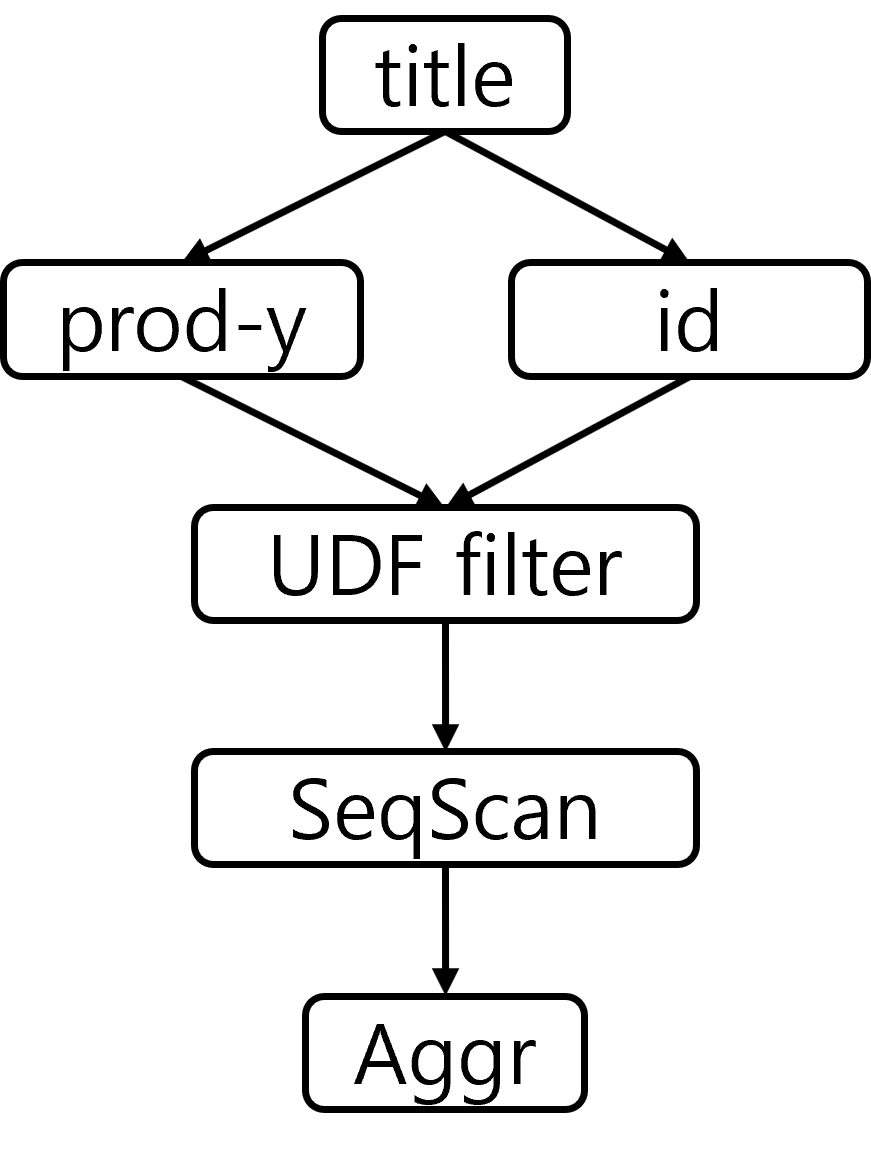
- UDF DAG
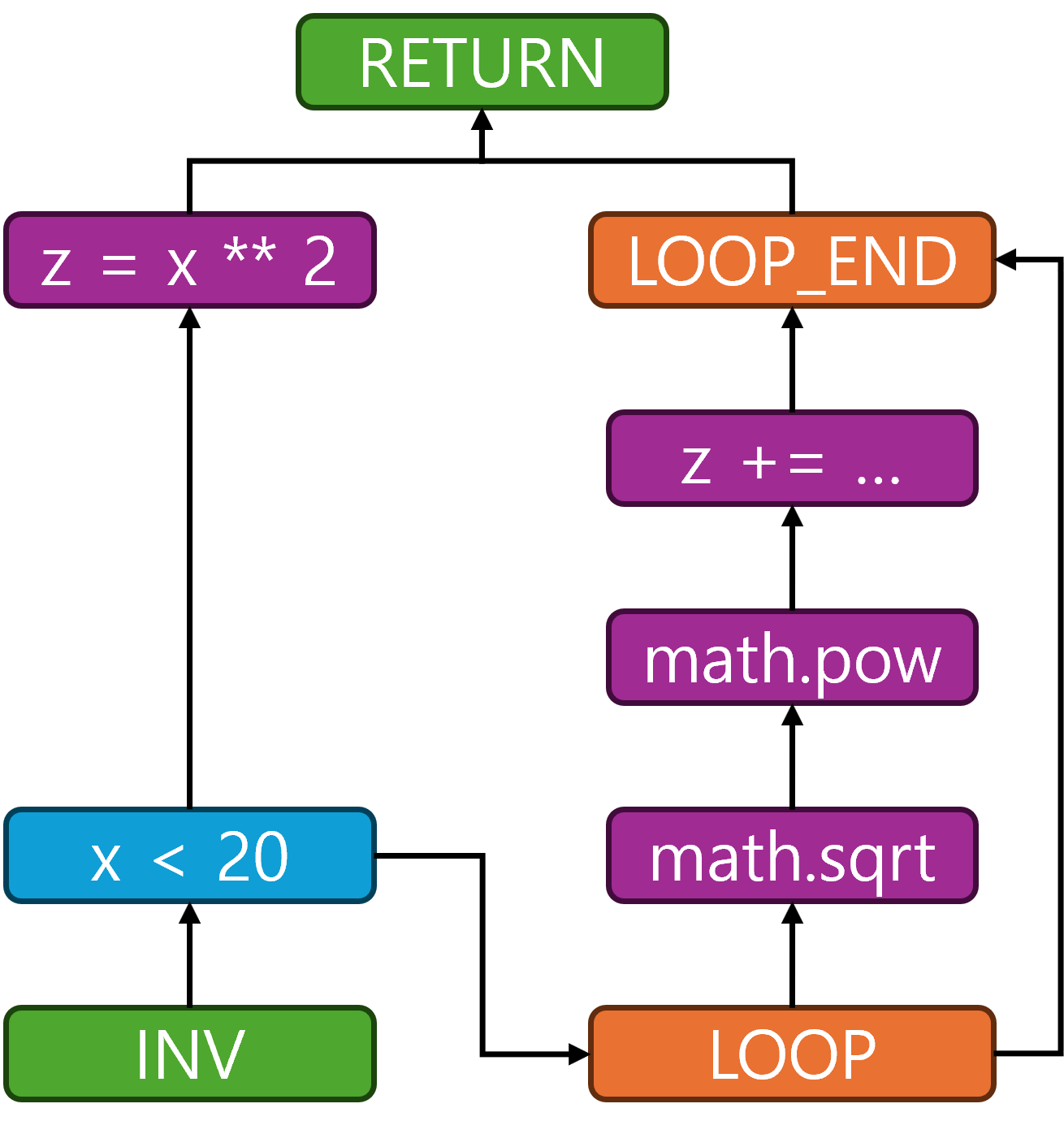
- SQL
- COLUMN → INV 연결 (Data Flow Edge)
- Query Graph의 COLUMN 노드들과
- UDF Graph의 INV 노드 간에 간선 생성
- 위 예시에서,
func(x, y)INV 노드와- title.production_year, title.id COLUMN 노드를 연결
- COLUMN → COMP 연결 (Data Flow Edge)
- computation 노드에서 직접 사용되는 입력 컬럼은 UDF에 바로 연결
- 위 예시에서,
x:title.production_yeary:title.idz = x ** 2는title.production_year와 연결z += math.pow(math.sqrt(y), i)는title.id와 연결
- RET → Query Plan 연결
- UDF가 selection에 사용되는 경우: UDF DAG의
RET노드와 Query Plan의FILTER노드 연결- 이때, Filter 노드에
on_udf = True라는 플래그를 추가 - 일반적인 predicate으로 구성된 selection은
on_udf = False
- 이때, Filter 노드에
- UDF가 projection에 사용되는 경우: UDF DAG의
RET노드와 Query Plan의COLUMN노드 연결 - UDF가 aggregation에 사용되는 경우: UDF DAG의
RET노드와 Query Plan의AGGR노드 연결
- UDF가 selection에 사용되는 경우: UDF DAG의
3.3.8. 최종 그래프 (Joint-Query UDF Representation)
3.4. Model Architecture
3.4.1. 전체 구조
- 모델 입력: Joint Query-UDF Graph
- Node Encoding: 각 노드의 feature를 dense vector로 변환 (node type 별 독립 encoder)
- GNN: Topological Message Passing (DAG 구조를 따라 bottom-up)
- Graph Embedding: Message Passing을 통해 하나의 joint representation으로 aggregate
- MLP (Regression)
- 모델 출력: Runtime Prediction
3.4.2. Node Encoding
- 각 노드 타입마다 feature schema가 다름
- 노드 타입 별로 별도의 encoder MLP를 설정
- Query side node types:
column,table,output_column,filter_column,plan,logical_pred - UDF side:
INV,COMP,BRANCH,LOOP,LOOPEND,RET
- Query side node types:
- Feature 종류별 처리 방법
- Numeric
- 스칼라 값 그대로
- e.g., cardinality, column statistics
- Categorical
- unique category가 32개 이하이면 one-hot
- 초과하는 경우 학습 가능한 embedding
- Multi-label categorical
- 각 라벨 임베딩
- 이후 각 임베딩을 bag-of-embeddings로 표현
- 남는 차원은 padding
- Vector
- 고정 길이 벡터 그대로 통과
- Numeric
- 각 노드 마다 해당 feature 인코딩 결과들을
- concatenation
- per-node-type MLP Layer
- output hidden state: $h_v^{\text{(0)}}$
3.4.3. Topological Message Passing (GNN)
3.4.3.0. Notations
-
$G = (V,E)$: UDF+plan을 나타내는 Joint Query-UDF Graph (DAG)
- $\tau = (s,e,t)$: canonical edge type
- $s$: source node type
- $e$: edge label
- $t$: destination node type
- $E_{\tau} \in E$: 타입이 $\tau$ 인 edge의 집합
-
$\delta$: $E \rightarrow \mathbb{Z}_{\geq 0}$: edge depth
- $h_v^\text{(d)} \in \mathbb{R}^H$
- depth $d$ 시점에서 노드 $v$ 의 $\text{hidden state}$
- $\text{MLP}_\tau$
- edge type $\tau$ 전용 combine MLP
- 파라미터는 $\tau$ 마다 독립
3.4.3.1. 위상 순서 부여
- Kahn’s algorithm으로 그래프르 topological sort
- 각 edge에 그 source 노드의 위상 라벨을
depth로 기록 (leaf = 0) - 이를 통해 “모든 predecessor가 확정된 후에만 노드를 갱신”하는 bottom-up 순서 보장
- depth 단위 노드 병렬 처리
3.4.3.2. Depth별 전파
- 특정 canonical edge type $\tau = (s, e, t)$에 대해, 이번 depth에 해당하는 edge 부분집합을 추출
- \[E_{\tau}^{(d)} = \{ (u,v) \in E_{\tau} : \delta(u,v) = d \}\]
- source 노드 $u$ 의 hidden state $h_{u}^{(d)}$ 를 메시지로 복사
- \[m_{u \rightarrow v} = h_{u}^{(d)}, (u,v) \in E_{\tau}^{(d)}\]
- destination 노드 $v$ 로 들어오는 메시지 합산
- \[\text{ft}_v = \sum_{u : (u,v) \in E_{\tau}^{(d)}} m_{u \rightarrow v} = \sum_{u : (u,v) \in E_{\tau}^{(d)}} h_{u}^{(d)}\]
- destination 노드 $v$ 의 hidden state $h_{v}^{(d)}$ 와 합산된 메시지 $\text{ft}_v$ 병합
- \[h_{v}^{(d+1)} = \text{MLP}_{\tau}([h_{v}^{(d)} \parallel \text{ft}_v]), \text{MLP}_{\tau} : \mathbb{R}^{2H} \rightarrow \mathbb{R}^{H}\]
3.4.4. Graph Embedding
- 별도의 global pooling / readout layer 미존재
- Bottom-up topological MP가 끝나면 DAG의 루트 노드가 그래프 전체 정보를 누적
- 이 루트(
plan0노드)의 최종 hidden state를 joint graph representation으로 사용
3.4.5. Runtime Prediction (MLP Regression)
- 최종 regression head가 스칼라 runtime 예측
- $\mathbb{R}^{H} \rightarrow \mathbb{R}^1$
3.4.6. Loss Function: Q-Error 기반 QLoss
3.4.6.1. 라벨 정규화
- QLoss branch는 log 변환 없이
MinMaxScaler(feature_range=(1e-2, 1))만 적용 - \(y^{raw}\): 초 단위 runtime
-
\([y^{raw}_{\min}, y^{raw}_{\max}]\): 학습셋 runtime의 최소/최대
\[y^{norm} = 10^{-2} + (1 - 10^{-2}) \cdot \frac{y^{raw} - y^{raw}_{\min}}{y^{raw}_{\max} - y^{raw}_{\min}}\] - 모델은 $y^{norm}$ 공간에서 직접 $\hat{y}^{norm}$ 학습 및 예측 → i.e., QLoss의 모든 항을 정규화된 $y^{norm}$ 공간에서 계산
- 따라서, $y^{norm} \in [10^{-2}, 1], \hat{y}^{norm} \in [10^{-2}, 1]$
- penalty term의 $(1 - \hat{y}_i)$: 상한 $1$ 기준 편차
- 과소 threshold $\tau = 10^{-3}$ < 정규화 하한 $10^{-2}$
- 정상 라벨 범위보다 더 낮게 예측했을 때만 penalty 발동하는 buffer zone
-
추론 시 역변환하여 초 단위 runtime으로 복원
\[\hat{y}^{raw} = y^{raw}_{\min} + \frac{\hat{y}^{norm} - 10^{-2}}{1 - 10^{-2}} \cdot (y^{raw}_{\max} - y^{raw}_{\min})\]
3.4.6.2. QLoss
- penalty mask (음수·과소 판별)
- 과소 threshold: $\tau$
- $\text{penalty}_i = 1[\hat{y}_i < \tau]$
- $\text{valid}_i = 1[\hat{y}_i \geq \tau] = 1 - \text{penalty}_i$
- penalty term
- penalty value: $C = 10^5$
- $p_i = (1 - \hat{y}_i) \cdot \text{penalty}_i \cdot C$
- valid term
- $q_i = \max(\frac{\hat{y}_i \cdot \text{valid}_i}{y_i}, \frac{y_i \cdot \text{valid}_i}{\hat{y}_i})$
-
최종 per-instance loss와 batch loss
\[\ell_i = p_i + q_i = \begin{cases} (1 - \hat{y}_i) \cdot C & \text{if } \hat{y}_i < \tau \\ \max \left( \frac{\hat{y}_i}{y_i}, \frac{y_i}{\hat{y}_i} \right) & \text{if } \hat{y}_i \geq \tau \end{cases}\] \[L = \frac{1}{N} \sum_{i=1}^{N} l_i\]
4. Pull-up / Push-down Advisor
4.1. Background: The Need for Cardinality Estimation
- 일반적인 Query Optimizer는 여러 실행 plan을 우선 생성
Plan A 비용 = ? Plan B 비용 = ? -
이후 여러 후보 plan 중 가장 비용이 작은 plan을 선택
- 비용을 계산하기 위해서는 연산자 자체의 비용 뿐 아니라 입력되는 Cardinality를 알아야 함
- 100 rows를 Join하는 경우
- 10,000,000 rows를 Join하는 경우
- 동일한 방식의 Join을 사용하더라도 위 두 경우는 비용이 완전히 다름
4.2. Problem Situation: Unknown UDF Filter Cardinality
4.2.0. Problem Situation
- 예시 SQL:
SELECT * FROM movie_keyword as mk JOIN title as t ON mk.movie_id = t.id JOIN movie_info_idx as mi_idx ON t.id = mi_idx.movie_id WHERE t.series_years = '1987-1997' AND udf(mk.movie_id, mk.keyword_id) <= 26026; - Optimizer가 알고 싶은 것: “UDF Filter 이후 몇 개 row가 남는가?”
- 그러나,
udf(A.x)의 내부 로직은 DBMS는 알 수 없기 때문에,selectivity = ?인 상태
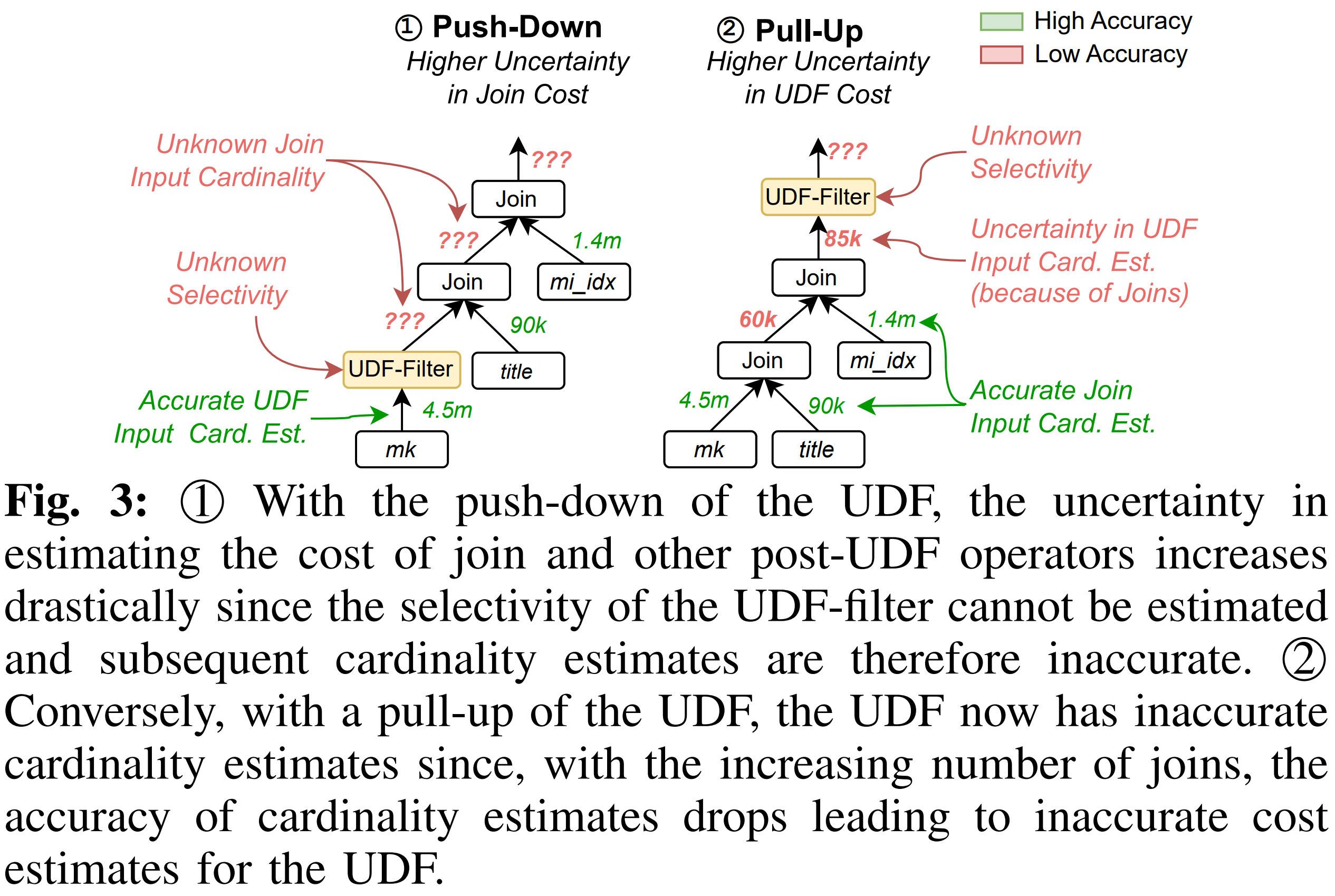
4.2.1. Problems of Push-Down
- Push-Down에서는 UDF를 가장 먼저 실행
- 이때까지는 상관이 없음
- UDF Input Cardinality를 정확히 알고 있기 때문 (Figure 3 예시에서 4.5m)
- 그러나, UDF Filter 이후의 Cardinality를 알 수가 없음
- 추정가능한 것은 UDF Input Cardinality와 동일한 fixed upper bound 뿐임
- 따라서,
- UDF 이후의 Join 입력 Cardinality: Unknown
- 그 다음 Join 입력 Cardinality: Unknown
- 최종 Cardinality: Unknown
-
연쇄적으로 Unknown Cardinality가 누적됨
-
이러한 Unknown Cardinality는 Join Cardinality 뿐 아니라 Join Cost도 Unknown으로 만듦
Join 알고리즘 특징 적합한 상황 Nested Loop Join (NLJ) 바깥 테이블의 각 row마다 안쪽 테이블을 탐색 입력이 매우 적거나 Index가 있을 때 Hash Join (HJ) 작은 테이블로 Hash Table을 만든 뒤 Probe 대용량 Equi-Join에서 가장 많이 사용 Sort-Merge Join (SMJ) 두 테이블을 정렬한 뒤 Merge 이미 정렬되어 있거나 Range Join일 때 - e.g.,
- Input Cardinality 100 rows -> Nested Loop Join
- Input Cardinality 10,000,000 rows -> Hash Join
- e.g.,
4.2.2. Problems of Pull-Up
- 기존 Join 들은 DBMS Cardinality Estimator가 비교적 잘 예측
- 그러나, Join을 여러 번 거칠수록 Cardinality Estimation 오차가 커짐
- 이에 따라, Pull-Up의 경우, UDF Input Cardinality가 부정확함
- Figure 3 ②, “Uncertainty in UDF Input Cardinality Estimation (because of Joins)”
4.2.3. Comparison of Push-Down & Pull-Up Problems
| Push-down | Pull-up |
| ----------------------- | ------------------------------ |
| UDF 입력 Cardinality는 정확함 | UDF 입력 Cardinality가 부정확함 |
| UDF 출력 Selectivity를 모름 | Join Cardinality 오차가 UDF까지 전달됨 |
| 이후 Join Cost가 불확실 | UDF Cost가 불확실 |
4.2.4. GRACEFUL’s Approach
- 기존 Optimizer는 Cardinality를 점추정(하나의 단일 스칼라로 추정)하여 Cost를 추정
-
그러나, UDF가 있으면 이 Cardinality 자체를 알 수 없음
- 따라서, GRACEFUL은 여러 UDF-Filter Selectivity에 대해 반복적으로 Cost를 추정하여 Cost Distribution을 생성
- 이 Cost Distribution을 바탕으로 Pull-Up과 Push-Down 중 어느 플랜이 더 안정적이면서 유리한지를 판단

댓글 남기기